Leaderboard




Popular Content
Showing content with the highest reputation on 2021-07-30 in all areas
-
I've played 0 A.D. for quite some years, and though I congratulate the team on its historical focus, I do at times crave the thrills of ahistoric and even supernatural elements which I originally experienced in games such as Age of Mythology. Recent glimpses of 0 A.D.'s new campaign system have reinvigorated my imagination in that regard, with thoughts of Robert E. Howard's "Hyborian Age" coming quickly to mind. Let me state at the outset that I am no programmer. I may be able to cobble together and modify bits of code, given enough examples, but a mod that transforms 0 A.D. into the Hyborian Age is quite beyond my capability. The same goes for art assets (a bit of SketchUp is all I'm good for), and even the knowledgeable pairing of Hyborian source material with its historical analogues might be biting off more than I can chew. My goal in starting this thread is simply to get a feel for what's involved in creating a mod of that caliber, solicit the opinions of those familiar with both Howard's work and the innards of the game, and hopefully gain some level of comprehension as to whether I would even have a place in any such project, should it someday be attempted. Off the top of my head, here are a few thoughts.... The peoples of the Hyborian Age bear the hallmarks of various real-world civilizations, often stereotypes meant to quickly paint a certain picture in the minds of the early 20th century pulp magazine audience. This means that some modifications might be as simple as altering the names of existing 0 A.D. elements, or patching together different units and buildings to synthesize something "new". An Hyborian Age mod would likely be best as a world map and/or a series of regional maps, all with story features, landscapes, and cities immutably placed. There would no point in mixing it with actual historical factions, except for sheer novelty. This means that the mod might be a "full conversion" rather than an add-on. How that factors into keeping it up to date, I do not yet know. Ideally, the mod would be based on Howard's work alone. There might be room for cross-overs with the works of his contemporaries, and perhaps even the posthumous edits and pastiches that came decades later, but the core project should focus on a purely-Howardian experience.4 points
-
I will give you some hints on how to start the first minute and what you should aim for. The idea is to pump out units initially as fast as possible. You will outproduce the very easy AI. I would suggest doing these moves at the start, which work on most maps. 1. Click on your Civic Center. Then press ctrl+z to train a batch of women. We train batches of units if possible, since training in batches speeds up the production and allows to produce more units per minute. 2. Order your women to gather berries and your camel rider to hunt chicken 3. Order 2 of your men to build a farmstead near your berries such that your women gather more efficiently. The other 2 soldiers can build a house and a storehouse. 4. Click on your Civic Center again. Press ctrl+1 to put the CC on a control group. When the CC is selected click on a tree to place a gather point. Once the women are created, they will now directly go and chop wood.. 5. Wait until the women are nearly ready. When they are, press the shift button and use the mouse wheel to change the batch size. You should set the batch size such that it is the maximum batch size you can afford. 6. As soon as the farmstead is build, you should do the berry gather upgrade and move the infantry that build it and order them to gather wood. The idea is to train the maximum batch size you can afford. Also make enough houses to be able to support the population. In order to do so, you need to press 1 (assuming you set the civic center on control group 1) and see how long it takes before you need to order a new batch. At some point, your berries run out and you need to think of a new source of food income. To keep your Civic center producing constantly, you need around 10 farmers or 4 berry gathers After some time, you can afford a barracks. Again it is the idea to put the barracks on a control group and constantly produce. You need to remember that once you get the barracks, you will need more food income to keep it running, so you probably need to add 10 farmers. The more units you produce, the more resources you gather and thus the more you can spent and the more barracks you will need in the end. Strategies can vary, but you will most often need at least 2 barracks before going to p2. Once you are thinking about going to p2, you have more freedom to decide what your priorities will be. The key is to adapt to your resources. If you are floating wood, you can spend extra wood by building pikemen from your CC, construct buildings and do the upgrades. If you are short on wood you probably make mainly women from your CC. Also if you can move camel archers and do economy at the same time, you can do a camel rush. However as a new player that might be too taxing on your skills.1 point
-
I think it's not possible. Ninja doesn't support those. I personally didn't try using it with anything besides vs2019 with win10 toolkits, so I am not too familiar with that, but I recall reading something like that, not entirely sure.1 point
-
Thanks for the report -> this was actually a bug in the C++ height map loading code, hence why it happened there.1 point
-
Not more than documented here: https://trac.wildfiregames.com/wiki/EnglishStyleGuide, I think.1 point
-
Moderation: Split the discussion of building a 64-bit pyrogenesis into its own thread, as it had deviated from the original purpose of this one.1 point
-
oh. Hmm. Well back to chopping wood.1 point
-
I actually started developing a mod with precisely this theme from alpha 23. I even got pretty far with it. I had several kingdoms well fleshed out and playable in game, however a couple of issues dissuaded me from continuing to work on it after alpha 24 dropped: The copyright status of Howard's work is difficult to assess, at least in my country. Due to being published after his death, I've read that parts of his Hyborian Age lore have not yet entered the public domain here, and thus determining which ideas fall under which legal regime will take a lot more painstaking research than I am willing to commit to. The martial world building of the Hyborian Age is a lot less fleshed out than one would expect (at least in the subset I've read). While there are tidbits of cultural differentiation in the text, like the idea that the Shemites are the best archers in the world, there's not a lot in the text to back up what those characterizations mean in practical terms. Basically every "civilized culture" Conan encounters fight using devastating heavy spear-cavalry, supported by pike infantry (who get talked up a lot but never do anything except die), and superhumanly skillful foot archers. All wear predominately chainmail armor. The barbarians are all unarmored foot infantry with javelins, swords, daggers, and clubs. In any sort of prolonged mundane combat it is always the archers who are described as being decisive, while for shorter skirmishes or when there is supernatural or heroic intervention in the mix, it's the cavalry. In short, the martial world building in Hyborian Age stories is mostly about creating a mood to frame the heroics of the protagonist. If one wants to build a well differentiated and balance strategy game from that foundation, it is obligatory to seek for the preponderance of ones inspiration from outside the actual texts, while discarding a lot of Howard's own characterizations, at which point are you really making a Conan game? Between these two issues, it makes more sense to me to create a derivative original fantasy setting, over trying to actually adapt Robert E. Howard's work. That said, the appeal of the concept is not lost on me, and there were some things in my experiment that definitely worked really well: The promotion system for one really sold the idea of a power curve, where individuals could differentiate themselves by heroic achievements. Auras also really fit the setting.1 point
-
Because Fremen in the desert wearing black for camouflage makes perfect sense... That was a weird movie.1 point
-
I actually made an attempt at a historical reconstruction of a Greco-Bactrian temple in Blender. It's not really finished and I wanted to render a higher quality video, but my laptop will explode if I try. Anyway, you're free to use it as concept art. I just uploaded what I have to Youtube. The Temple With Indented Niches, in Ai Khanoum, Afghanistan, 3rd-2nd century B.C.. Some artistic liberties were taken with those triglyphs and metopes for example. Not entirely without justification, but still a little unlikely, I admit. The interior is also mostly educated guesswork. Some renders: For those of you curious about trying out Blender, here's a quick illustration of my progress: With well over a million tris it goes without saying that this not suited for the game. But it could serve as inspiration for the Greco-Bactrian temple. I'd love to see this faction become part of the game...







 1 point
1 point -
probably should, but not as a bugged code1 point
-
As it turns out the answer for this is we know almost nothing about the punic sacred band, even the name we know might be misleading. I find it very interesting that this came up here as I just read about it a couple days ago https://www.ancientworldmagazine.com/articles/punic-sacred-band-clearing-up-confusion/1 point
-
Snapping: Territory decay: Triremes: Roman army camp: Autoqueue: Carthage Sacred Band: Catapult: Embassies & Mercenary Camps Experience trickle: Fishing: Forge: Gathering: Kush Pyramids: Outposts: Palisades: Quinquereme: Resource counter: Map flare: war elephants whales Forge Formations Biomes Iberian Fireship Tresures Barracks Cavalry stables Elephant stable




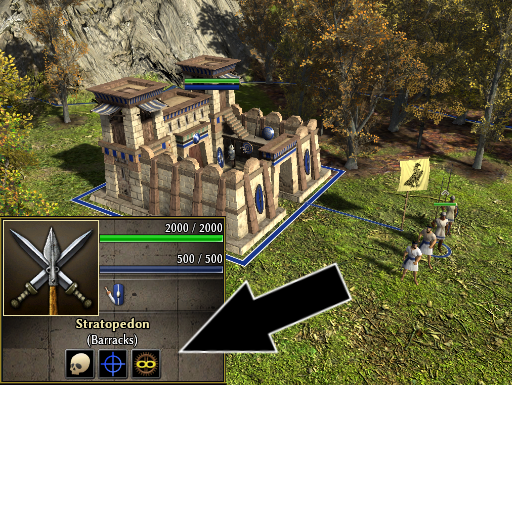

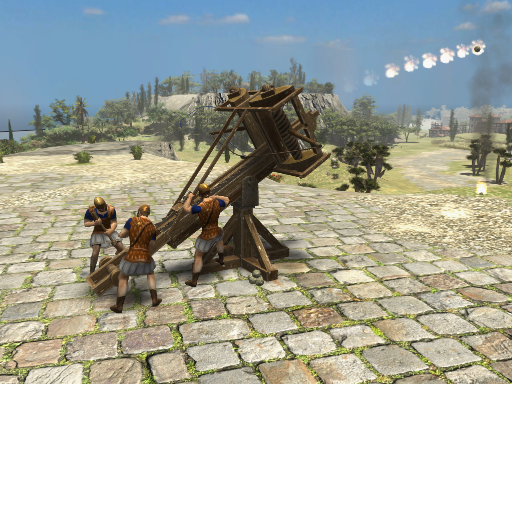










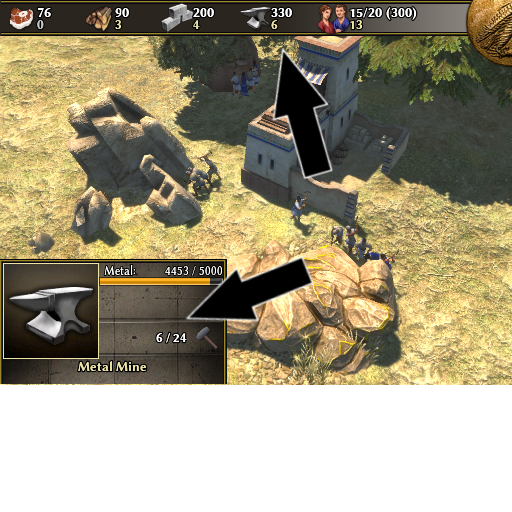
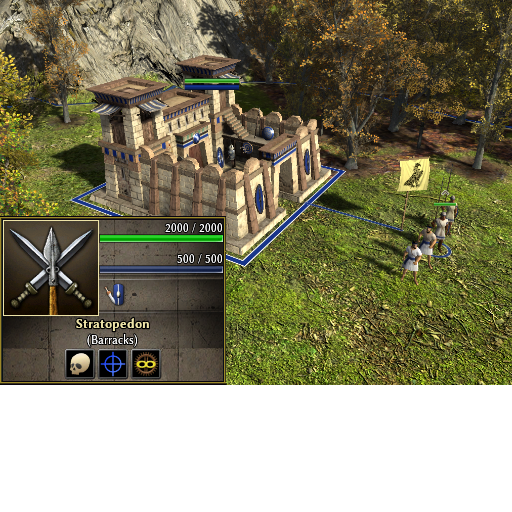










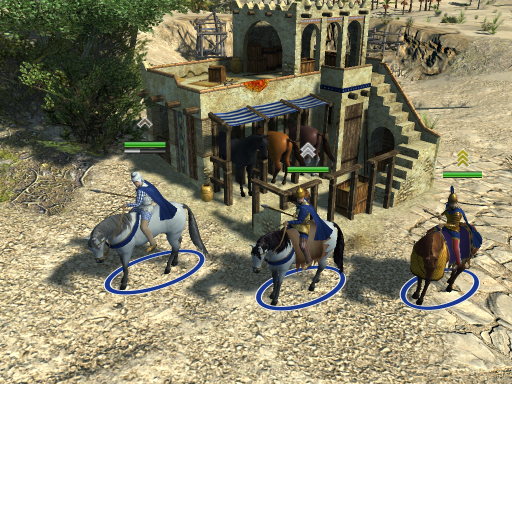

 1 point
1 point -
0 points














.thumb.jpg.b85f1db9873287a0d10cd2c7e88579c0.jpg)

.thumb.png.ce58cea22940c255f5b0a735d5abee36.png)