Leaderboard



.thumb.png.ce58cea22940c255f5b0a735d5abee36.png)
Popular Content
Showing content with the highest reputation on 2015-04-03 in all areas
-
Hi I am lexa from split-bot in case some of you rember I am an active member of Silex Labs, a non profit organization which aims at helping people contribute to free and open source projects. We organize events in Paris, mostly work shops and sometimes a big conference for Haxe (next one is in may, with all the core contributors and community) Next week we have decided to start a series of workshop on programming 0ad bots. 2 workshops of 2 hours are planed to start and see how it goes (this link is in French) Has anyone already organized events for 0ad community? If you have any idea, recommandation, please tell me Please let the world know about this initiative and the other activities of Silex Labs (see April news letter or the blog) And let's hope that this will unveil new french contributors to 0ad!2 points
-
Using this diffuse map, parallax won't look good at the seams. It would have needed to have a bit of padding around the edges of each texture piece, but that would also waste texture space. A single tiling texture would have been best for this. Perhaps future OpenGL will remove the need to construct these texture-atlases (which would certainly be a blessing to us art-devs). Then again, parallax is kind of overkill for this game (you got to soom way in so even see it). Normal maps should be fine. So, since texture atlases are bound to stick around for quite some time, I would recommend that these texture include a bit of padding around each texture in the future. When scaling they smear together, and producing normal maps are a PITA, and parallax occlusion won't look good.. all due to the lack of padding (it would waste a bit of texture space, but it's worth that cost). I'm working on removing the baked shadows in the diffuse texture now, side by side comparison so far:
 2 points
2 points -
Great reference, could be Imperial Romans temple. I enjoy the travertine walls.1 point
-
I think the comment from fcxSanya was a valid one. You can't get results from grep back if you spell it wrong. And it's important for everyone who helps out here that they see the command given was invalid. The bold text also isn't agressive if that's what you mean, it's just used to highlight the difference.1 point
-
It's called libCollada, not libColldata1 point
-
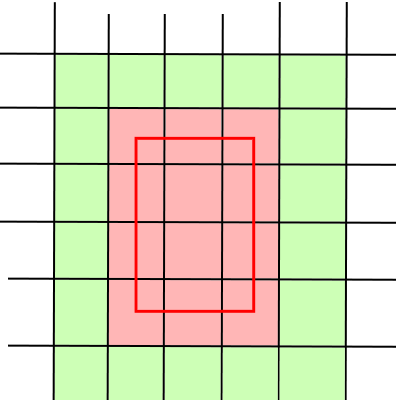
I'm going to try a new format for the spatial subdivisions which would remove the need for uniqueness sorting, potentially improving efficiency. Basically it's like spatial subdivisions but subdivisions would be a lot smaller ( like about a big bigger than a building footprint, so that most entities boundaries are smaller than a single subdivisions). You only add entities to the subdivisions their center is in, and when you range-query you return the subdivisions around your query too (see schema) sp that you're sure to get it. Entities that are too big would not be put in the subdivisions but at the basic level, so all entities would be considered "close" to all other entities. If we can manage to have few enough of those, this should work well. On the schema, the black lines are subdivision limits, the red square the range query, and the reddened squares are what would be returned by the existing query system, which needs to be sorted for uniqueness, while my method would also return the green squares, but won't sort. So maybe that'll be faster, maybe it won't be, we'll see. My hope is that if we make subdivisions just bigger than most item bounds, we'll have small subdivisions so we wouldn't add too many items, yet it'll be quite efficient since it's still all vectors and mostly static, and we won't have to worry about doubles and stuff like that which would allow faster queries. Maybe.
 1 point
1 point -
I saw this one, but someone knows about it?1 point