Teiresias
-
Posts
32 -
Joined
-
Last visited
-
Days Won
2
Everything posted by Teiresias
-
A way of unit-testing AI code using jasmine
Teiresias replied to Teiresias's topic in Game Development & Technical Discussion
Itms, thanks for the "padding on the shoulder". I admit I might be a bit extreme regarding testing, since I partially do this for a living. Regarding your question I'm afraid, no. When writing jasmine tests I am in a JS-only world. Since a unit test is about testing the smallest isolatable parts of a software system - usually a single function or a class - this is not a problem for me. But if you intent to include the Pyrogenesis engine activities together with the JS code - that's actually an integration test, and usually harder to acchieve than unit testing. I don't know any off-the-shelf solution, in particular if multiple runtime environments are involved (native code vs. SpiderMonkey JS environment). In my AI experiments I faced similar problems with the common AI and currently use two approaches: Include the common AI code in the JS space where the jasmine tests execute. Since they are both JS this is possible. However, I still try to avoid this as much as possible since it introduces an external dependency. Lift up to system test level, i.e. run the whole Pyrogenesis executable in autoplay mode with special script files to generate a scenario map tailored for testing and evaluating the AI behavior. This is a very cumbersome method and I try and avoid it whereever possible. No JSCover analysis done with this method. -
Questions on AI API3 template handling
Teiresias replied to Teiresias's topic in Game Development & Technical Discussion
In my AI scripting experiments I also use negative values to indicate "this resource amount still has to be gathered to do that" (not compliant with a schema but still working fine). -
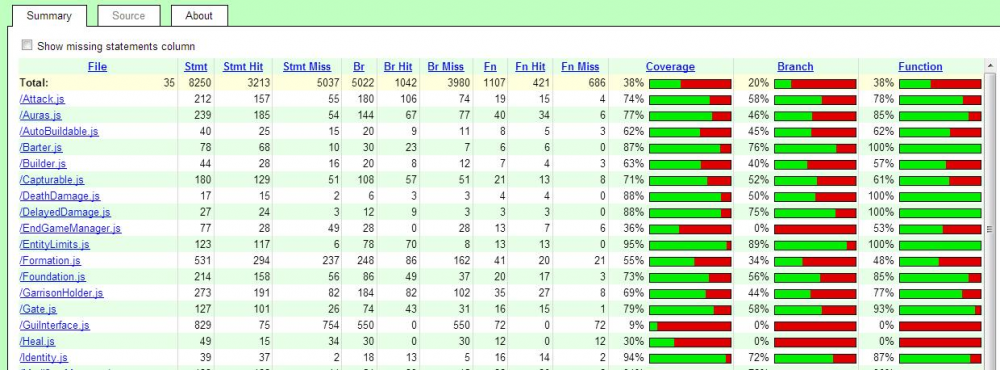
While discussing a quirk of the common AI API on IRC Stan suggested to take a code coverage measurement on the existent simulation components, since I had the toolchain already set up for AI development. I took the challenge and now present first results. However, I decided to not attach this to the already running jasmine-thread since I consider it an independent topic. To reproduce the measurements: Attached to this posting is a zip archive. Unzip it to binaries/data/mods/public/simulation. A new directory CoverageMeasurement will show up. Inside that directory, the subdirectory instrumented already contains the results of an instrumented run. Load the jscoverage.html file into a fully-scripting-enabled browser to see the results. They will look somewhat like this: To rerun the analysis, launch the runcomponenttests.sh shell script from the CoverageMeasurement directory. That script requires that the zip archive has been unpacked at the particular destination and 0AD fully compiled (SpiderMonkey shell is compiled via the update-workspaces.sh script). Observations during analysis: The test scripts are normally run from the pyrogenesis test script file test_scripts.h via the cxxtest subsystem. This means the scripts can enjoy the full Pyrogenesis environment, which is not available when runcomponenttests.sh runs the test scripts via SpiderMonkeyShell. For example, I had to manually define all interface identifiers IID_XXX in the jscover-driver.js file which contains the actual 0AD-specific analysis logic. Since I just faked the missing Engine functions, the logic of some test cases might not work, giving improper coverage results. Still, I found some component methods which seem to be not tested. My homebrew driver script runs all test scripts in the same JS environment without resetting the global scope. This caused SpiderMonkey errors when const values were redefined. To overcome this, the shell script wraps the content of each test script into a "(function () { test script })()"; encapsulation using an sed script. Some test scripts still caused errors and I resorted to skipping them for the first draft. Error analysis seemed too cumbersome when it is unclear whether this approach is feasible at all. The skipped test cases are marked in the CoverageMeasurement/jscover-driver.js file. Code coverage measurements are taken via the JSCover tool (not the most recent version). This tool is originally intended for web development and so relies on running a JSCover server in the background, while browsing the reports. I hacked the JSCover main script to allow browsing the results without the server running, as this was needed to integrate the JSCover results into a JSDoc documentation site. The hacked jscoverage.js script is found in the CoverageMeasurement/JSCover directory. Any comments or questions welcome. CoverageMeasurement.zip
-
- 3
-

-

-
- code coverage
- javascript
- (and 2 more)
-
In yesterdays IRC I mentioned about using jasmine tests for AI development and the topic was considered as maybe of interest to others. So I hereby provide a trimmed-down demonstrator on how a test suite can be set up. The attached zip archive contains a copy of the API3 AI high-level interface with two test cases (one of them discovered the problem discussed here), plus the necessary infrastructure (jasmine 3.6.0 release and driver html page). To execute the test cases, just extract the zip content to some directory and load the common-api/jasmine-runner.html file into a scriptable webbrowser. Said html file is commented to show how the jasmine framework, the API3 under test and the test files interact. Items to consider: For the demo, I used the official jasmine standalone release which contains a version number in its path. In "production use" I rename the directories to get rid of the version number so no changes are needed when upgrading jasmine. It is also possible to execute the unit tests via the SpiderMonkey js shell by loading all of the scripts and running the jasmine bootstrap code. I also managed to connect the jasmine test suite to the JSCover code-coverage measurement tool, but this requires a more complicated setup, i.e. a list of all source and test case js files plus a platform-dependent batch job and a hacked-up JSCover driver js script. I can provide a demonstration if there is interest. Any comments welcome. jasmine-demo.zip
-
Questions on AI API3 template handling
Teiresias replied to Teiresias's topic in Game Development & Technical Discussion
Thank you for the explanation. Your assumption may still hold, as I constructed the raw template data programatically (similar to the demonstrator in the first post) and this way bypassed the schema at all. I can live with it, I was just wondering if I am using the API3.Template class in wrong matter - before constructing a load of code doing so. -
I tried playing around with the AI API3 and set up my own entity template. Thereby I noticed an interesting behavior of the API3.Template.cost() function. I extracted a demonstrator for it: If you execute the following snippet (function (){ var rawTemplate = { "Cost" : { "Resources" : { "food" : 1, //"wood" : 2, "stone" : 0, "metal" : 4 } } }; var fakeSharedAI = { "_templatesModifications" : {} }; var testee = new API3.Template( fakeSharedAI, "someTemplate", rawTemplate); warn("Costs are " + uneval(testee.cost())); })(); in the content of an AI script (e.g. inject it into petras start-up sequence), the 0AD log receives the following entry: Note the NaN in the second property. So it seems template instantiation accepts skipped resource definitions gracefully, but I do not understand the behavior on "stone":0. Am I doing something wrong? I imagined something like "{food:1, stone:0, metal:4}" to build up.
-
Hi stanislas69, i have already tried introducing JsDoc some time ago with focus on the AIs and we had a discussion about it (see https://wildfiregames.com/forum/index.php?/topic/19488-proposal-enhance-common-api-with-documentation/). At that time a big obstacle discovered was that JsDoc used a different JavaScript interpreter than 0AD itself: Rhino vs. SpiderMonkey. I don't know whether this has changed by now, but at that time it seemed like the 0AD JavaScript code was compatible only with 0AD itself, as SpiderMonkey seems to be the spearhead of JS development. Any separate tool using a different analyzer may introduce troubles. Quoting mimo: If it has JS compatibility issues which prevent us from using some JS features that we would want to use, that's a very strong point against its use. What is your concept for handling this problem? (Sorry for the less-than-optimal layout - my browser has severe problems with the new forum editor which i have not resolved yet).
-
Sorry - posted into wrong thread. Discussion is continued here: https://wildfiregames.com/forum/index.php?/topic/20728-jsdoc-documentation
-
Any start point for AI development?
Teiresias replied to analca3's topic in Game Development & Technical Discussion
The question of getting involved with AI development comes up from time to time. General consensus seems to be that indeed you start by digging through the sources and modify the existant bot to your needs. You say you "need to do a BIG BIG work with AI" - is this a master thesis or similar? If so, i suggest to check with your mentor before starting: The AI API is not stable and requires adjustment of the bot script code from time to time. See here. If you are doing a thesis work with a deadline, it may be advisable to check out and freeze a specific revision to prevent your module from getting broken at an undesirable time. Will your work have to become part of the official code base to be accepted in studies? If so, approach #1 is probably not feasible.Regarding the non-existant documentation, this has been discussed before - and it seems consensus that the difficulties caused by having to "read the code" are neglectible compared to building up your own concepts. The ultimate goal of an AI is to give the user (player) a challenging and fun experience. This is more of passing the turing test than building algorithms/structures. Besides the tutorial already mentioned, additional information may be gathered in the forums by searching for "AI", "petra", "aegis", "jubot" etc. -
An event in Paris about 0ad to find contributors
Teiresias replied to lexa's topic in General Discussion
lexa: JuKu96 has created a tutorial on bot development some time ago. Additionally, you may check the forum topics tagged "AI", but afaik not all relevant threads have been tagged. Seconding sanderd17, the AIs of 0AD evolved gradually from the ancient "testbot". It was implemented as a demo by the one who implemented the original AI interface into the engine. To quote sanderd17 from #0ad: 21:52 < sanderd17_> The first AI was only meant as a test IIRC, but sadly, it kept growing bigger, until it became a monster. Friendly spoken, the AI is not designed but grown. So, there seem only few high-level designs/planning documents available. I doubt the AI<->engine concept will be changed at a whole in the forseeable future, but i recommend you to practice some hours on your own before giving the event. Regarding your planning, two times two hours might prove a bit short in time. You might want to chat to mimo about a good "place to enter". Another option is to fetch a copy of testbot/jubot from an earlier SVN version and adapt it to the new API, to use as a "drosophila". -
Request for Comments: Hannibal Group Scripts
Teiresias replied to agentx's topic in Game Development & Technical Discussion
I think there are two fundamental improvements in your concept: Regarding performance, the event-driven approach is probably far superior to any polling system based on entity collections, as supplied with the current API. If driven far enough, maybe you could do away with the BaseAI.handleMessage() alltogether. IIRC that function has been identified as a performance dropper in some forum discussions. Your DSL nicely abstracts off the tedious details of reading templates, isolating entities etc., which tend to clutter up the JavaScript code of the current bots (including mine).Generally, your DSL and event system implement an expert system somewhat similar to what was used in AoK, but at an entity-level granularity. This is probably more suited to defining intelligent behavior than pure JS. Looks promising! PS. I meant SDK=Software Development Kit. I was not sure whether you will provide a complete set of scripts or whether Hannibal is just the pure "script runtime". -
Request for Comments: Hannibal Group Scripts
Teiresias replied to agentx's topic in Game Development & Technical Discussion
I think av93's question shows an interesting point, which seemed swinging along "under the hood" of many AI-bot related discussions: Shall we concentrate all efforts on one - *THE* - 0AD bot for extraordinary quality and glory, or are we going to look at/for a zoo of different bots and concepts, so the best concepts will eventually evolve? Personally i tend for the second option, but there seem quite some people in favor of the first one. @agentx: In your initial post, you state "because this what this bot is all about.". I get the impression Hannibal is more of a new "AI-bot SDK", than a bot. In your second post you say "Depends on the group script author. He/she may use:...". So will the bot behavior be hand-coded, or are you going to infer the group scripts from the triple store? -
at l(e)ast we have a larger discussion group now... I will try and answer all points of the previous comments: @feneur,mimo: I have choosen JsDoc because it seemed the best "Doxygen for JavaScript" tool available - there are not too many of them anyway. Of course, this concept introduces the dependency on the source code, and I had to learn the JS language changes much faster than do traditional programming languages. So this approach has its drawbacks. But, in my experience, a src->doc tool raises the chances of docs and src staying in sync, as both are "closer to each other". Separate documents tend to get neglected when the sources are updated, unless you have strict QA enforced. I even tend to write my designs into class/namespace overviews. @niektb,mimo: "struggled with basic tasks": I got a taste of it on my own today: In an attempt to write a quick-and-dirty driver for my defense system experiments, i attempted to use API3.Filters.byTerritory(), and failed to get it working. I found only one example of it in an elder aegis version, and that was not self-explaining. Finally, I considered it's faster to write my own version than debugging the existant one. @niektb: "unfortunately Aegis was difficult too": The elder testbot was simpler to understand, but has been dropped from the repository. @mimo: "improving the petra doc is in my plans, but I never find the time to do it": Based on my personal experience I can only recommend to write documentation immediately. Otherwise, you might never find the time once the task has grown real big. @agentx: "I've also thought of publishing here a minimal bot, (...) and you are knee deep in map analysis.": I can see that. Maybe this (c|sh)ould lead to a step-by-step tutorial which first uses a hard-coded bot on a hard-coded map, and then expands to more and more flexibility. "I agree with feneur that an invitation to AI devs needs more than a documentation.": I agree with you. I just stumbled on the problem to figure how to use some of the API functions and thought I could help to improve a bit here.
-
I digged a little deeper. Apparently, JsDoc uses a separate parser for reading .js files - currently, Rhino and Esprima can be used. None of them seems to support the for-of loop construct. With the Mozilla people marking these as experimental, the other JS parser/runtime implementors seem to wait on how the experiment turns out. It might be possible to patch Esprima's parseForStatement() function to accept the new style. I haven't checked that road: Judging by the results of this thread, noone is interested in a (Doxygen-like-)documentation of the bot API. Maybe the intended audience simply does not exist(?). So, i consider my proposal to be rejected.
-
@agentx: Trying out new ideas will still require knowledge of how to "read the game state/templates" and control the AI player's actionshow to fit in your idea into the current structure of the bot. For example, if you are preparing for an early mass attack with multiple barracks continually training, how to pre-set the economy to provide resources in-time.One can figure out all of this by just reading the sources, but it's probably becoming a challenge. @mimo: The compatibility issue is that JsDoc at the moment does not accept the following for-loop style: for (let id of data.ents) for (let [id, ent] of this._entities)I assume this is a new JS language feature introduced too recently for JsDoc to be already updated. At least, neither me nor any of my JS books knew of that style . If this is a problem, i may try and create a patch so the tool will accept that construct. Currently JsDoc reports a syntax error on these loops while parsing the sources. At two other points i went for a quick cut: Rewrote the API3.Template definition to not use the API3.Class({ ... }) constructor - it seems being phased out anyway. Removed the surrounding anonymous function constructs var API3 = function () { ... }(API3); from the source as they seem to have no effect but encomplicate namespace detection. I presume they are intended for closuring up global variables, but i have not seen any.At these two points, JsDoc accepts the source in its original shape but documenting it without these constructs was easier
-
Regarding the late game debugging, that's why i am using test suites so to catch at least the obvious faults before starting up a game. Currently i am just using Jasmine tests; but i am afraid for developing an attack/defense system i will have to build up a collection of system tests. This would mean specially designed maps with entities positioned to trip a particular behavior. Seems like a new real can of worms waiting for the tin-opener... But this is going off-topic. I still believe in future, the hurdles mentioned combined with "level of profession" of the then-already-existant AI(s) may limit the number of newcomers in this area more and more.
-
My idea is more of an API documentation/reference for the "customers" of the common-api (the bot writers) than the API designers. I got into 0AD AI programming by modifying testbot, which was a rather simple construction. With the AIs getting more and more advanced and the API following, i see the barrier for newcomers to raise. In my humble opinion, at least some parts of the common-api out-/bot-side interface require some degree of reverse-engineering to understand. I recall you saying "the hurdles to start with an AI are currently quite high". If this keeps on going, it might result in new people becoming more and more scared off because the interface feels overwhelming and "unfriendly". Besides, your second-last sentence "because it would help to design a new bot api" looks very interesting. Do you mean you'd prefer to discard the current bot/common-api system alltogether and re-start with a better design?
-
I have just started developing a more advanced(?) attack/defense system for AI bots. I feel the current common-api a bit hard to use: For example, in entity.js the definitions of entity and -templates are lined up one after another, with member functions not sorted. I (have to?) scroll through the whole file when searching for some entity property. So, i got the idea of improving. I have used JsDoc with satisfying results for documenting JavaScript code and applied it to a patched version of the common-api to get a doxygen-like representation. The tool is Apache-licensed, runs on (at least) Windows, Linux, BSD, and is highly customizable on the generated document format (see attachment description below). It should be possible to find or build a layout to fit nicely into the current 0AD documentation. Question: Is there any interest in "officializing" this approach, and to adapt the whole common-api for generated html-docs as in the attachment documentation-proposal.zip? Any comments welcome. The zip archive contains the following sub-sections: /common-api.original: The original common-api files for reference /common-api.jsdoc-compatible: A patched version. JsDoc does not accept the new Map-compatible JS loop style used in the EntityCollections. The module can be run within 0AD but i introduced some bugs (petra is training entities but does not gather/build at the moment)./common-api.documented: The patched version with documentation added./default-layout: The JsDoc output via the default JsDoc template/special-layout: The JsDoc output via the template i use for my AI experiments/documentation (based on an elder JsDoc version). A sample on customizing documentation. I can provide the template if desired.Notes: I have not adapted all parts of the common-api to not waste much efforts if this proposal is rejected. The description of the "EntityCollection" class gives a good idea on how the results may look like. As far as i know, Doxygen does not support JavaScript as an input language. There is a perl script which can convert JS sources into Doxygen-compatible C++. To me, this seems to much "make-do/Rube-Goldberg" style.
-
Accessability of methods/functions of "Engine"
Teiresias replied to Fluxkompensator's topic in Game Modification
I stumbled on the same question before. In short, not each part of the JS scripts can access each C++ method, they have to be reflected into the JS runtime beforehand. In detail: See /source/simulation2/components/CCmpAIManager.cpp - the CAIWorker is the C++ "driver" of a single bot afaik. At construction time, it initiates the m_ScriptInterface: m_ScriptInterface(new ScriptInterface("Engine", "AI", g_ScriptRuntime)) that's the "Engine" object you see in JS. Following in the constructor you see the functions being registered: m_ScriptInterface->RegisterFunction<void, int, CScriptValRooted, CAIWorker::PostCommand>("PostCommand"); m_ScriptInterface->RegisterFunction<void, std::wstring, CAIWorker::IncludeModule>("IncludeModule"); m_ScriptInterface->RegisterFunction<void, CAIWorker::DumpHeap>("DumpHeap"); m_ScriptInterface->RegisterFunction<void, CAIWorker::ForceGC>("ForceGC"); m_ScriptInterface->RegisterFunction<void, std::wstring, std::vector<u32>, u32, u32, u32, CAIWorker::DumpImage>("DumpImage"); So these are the functions of the Engine you can invoke from the AI. Note this list includes "IncludeModule" but not "QueryInterface" so a script cannot break out its sandbox directly. As a side notice, PostCommand is used heavily in the common-api scripts. Additionally, in /binaries/data/mods/public/simulation/components/ you'll find files named AIInterface.js and AIProxy.js; these are for passing the simulation game/state to the AI. -
@agentx, are you studying planning techniques as a pro? :-) I'm very interested to see how your planner comes up. I've already toyed around with the idea of a planning AI but without satisfying results. I faced two mental problems (have not experiments by now): Combinatoric explosion. As your state considers more and more game variables, maybe even including the entity layout on the map, i presume it will take more and more computing power to simulate the gameplay into the future? When driven at max, would the planner have to run a de-facto copy of the current game with the examined action taken, to find how it would work out? How do you set up the various operations for the planner - by hand or do you plan on parsing the entity templates (more or less) automatically?Do you plan to give the planner a rough route e.g. to reach city stage and a group of troups or, in the final version, will the planner start with the "simple" goal { isVictorious : true } to figure out everything on its own? @Hephaestion: Yes, i'm fiddling with a bot as well, but currently it's more a puzzle than a real bot :-( Still, made some progress in optimizing the gathering process. Still going slow, as i can just spend an hour or so per day on it, and tend to suffer a bit from analysis paralysis...
-
Where are you from?
Teiresias replied to Lion.Kanzen's topic in Introductions & Off-Topic Discussion
Teiresias was a prophet of Apoll, whom Odysseus called up from the dead while he stayed at Circe. He told Odysseus to leave the herds of Helios alone which didn't work out so well... It's an allusion of me being mostly silent/offline, only to show up from time to time to warn on upcoming troubles ;-) Sent from Germany @+2h GMT -
Question on upcoming git transition
Teiresias replied to Teiresias's topic in Game Development & Technical Discussion
sanderd17: If there will be zipped repros available (possibly split into smaller packets) this might help. Besides... What happens when the git equivalent of "svn update" is interrupted? Can that action be restarted or would it screw up the local repository? Hephaestion: My internet connection is quite unstable, and for "logistical" reasons i simply cannot keep my machine online for more than an hour/day or so. When i started digging into 0ad, i had the svn check-out running in the background while i was online, slowly "trickling" the repo down. So, if there were only "git clone" available for getting 0ad, well... Then i'd simply have to part with it. -
Hello everyone, browsing yesterday's IRC logs, it appears to me more and more members of the Wildfiregames team are using a github repository for development now. This seems logical given that git is supposed to replace the current SVN-based repositories in the future. As stated in the elder git migration forum thread the 'final' git repository of 0ad will be located on the trac server. As i learned from IRC and confirmed by web search, connecting to a git repository requires an intial "cloning" which downloads the complete repository on the local machine. The problem is that operation is unforgiving: Unlike svn, any interruption of the clone operation causes git to re-start the whole download operation. Some googling shows that effect is known since 2009 and fixing it seems hard (if possible at all without breaking backward compatibility, see 3rd post of linked forum thread). So it seems unlikely this limitation will be removed in the forseeable future. Moreover, the maiority of git(hub) repositories seem rather small compared to 0AD, so there is low pressure to put efforts on it. In short: The svn-git migration might effectively lock out at least some newcomers from the project as the git clone-non-resume problem demands an initial uninterruptable download of several gigabytes (according to Philip on IRC, 2GByte at the moment). I imagine the problem will grow in the future (literally). I see at least three ways of dealing with that: Keep the current parallel SVN|git system, maybe with an auto-converter between them. If there is a way to convert existant .svn checkouts to git, a migration might be possible (git svn seems capable of resuming). Just switch off the SVN repo at day X and tell the people outside to either help themselves or go . Any comments or official statements available?
-
Advice on tracking AI bot API changes?
Teiresias replied to Teiresias's topic in Game Development & Technical Discussion
sanderd17: "If you use SVN, you don't have to download 5GB every day." - how about the pending git migration? I don't know git at all, but assume its similar to Mercurial (which i use locally). Will i have to download the whole repos again when migration is complete and SVN shut down? -
There seem at least three people thinking/working on AI bots - wraitii, agentx and me. Last night it sprang to my mind what happens when the bot API changes in a non-backward-compatible way. By now, there have been four APIs (common-api, common-api-v2, common-api-v3 and now the new common-api). Additionally, bots might be analyzing the engine messages directly, bypassing the common-* stuff for performance. So the data formats used by the engine might qualify as "API" as well. At least the following ways could be used to deal with changed APIs - each of them has its problems: Do nothing and if there is a crash, either the author fixes it or, in case of abeyance, the AI is finally dropped from the repository. This happened to testbot, jubot and scaredybot. Sub-optimal when a bot is partially broken and noone files a bug report (at the time when it's still fixable). Advise people against writing bots until 0AD has "gone gold" and the APIs are stable. At that time, it is by definition too late to change the API should a common desire arise to do so. An API version number could be implemented which increases on changes and the bots quit when the version is too new. Something similar is already happening when the common-api-v* versions are used, except the count has been "reset to 1" now. Problem is that backward-compatible changes might screw them up, causing unnecessary annoyances (google for the Haskell fixed-upper-bounds problem...) At startup, each bot runs test routines to validate the API still behaves as expected, and if not, emits warnings/errors. This seems promising, but might require a multiple of plays on different maps to trip a test to fail (e.g. some test checking dock placement and bot is played on 'dry' maps only). The bot author could run a series of test scenarios, maybe including custom-built maps, to check h(is|er) baby for misbehavior. I think this is the most effective but also most laborious way to do it.While the latter two methods are real labour-intensive, they would give hints on which parts of a bot are in trouble. I do some 'dry' testing using jasmine for it's faster than starting a game and waiting to spot a particular behavior/bug, but only so far as the 'innards' of the bot are concerned. Any recommendations?