Leaderboard



Popular Content
Showing content with the highest reputation on 2022-12-19 in all areas
-
Don't take the title seriously. What i am writing is my view and not that from the WFG-team. I try to speed up the engine and make it less stuttery. First I was locking at multi-threading. Since "if one core is to slow multiple will be faster" right... In the most recently uploaded CppCon-presentations about Hardware Efficiency and General Optimizations this statements were made: "Computationaly-bound algorithms can be speeded up by using multiple threads" and "On modern hardware applications are mostly memory-bound". It seems impossible or hard to speed up an application using multiple threads. But step by step: Computationaly bound is when the speed of an application is bound by the speed of computation. Faster computation does not always mean faster application. A webbrowser is likely network bound: A faster CPU does not improve the application speed by much but improfing the network speed does (It can also split up in latency-bound and throuput-bound). An application can be bound by many other things: GPU-bound, storage-bound, memory-bound, user-bound An application is fast if no bound does outweight the others. In the last decades CPUs got smaller (smaller is important since that reducec latency) and faster. -> Computationaly bound application became faster. Memory also got faster but is spatially still "far" away from the CPU. -> Memory bound application became not so much faster. There is some logic that can help us: We have to bring the data (normaly inside the memory) spatially near to the CPU or inside it. That's a cache. If the CPU requests data from the memory the data will also be stored inside the cache. The next time it is requested we do not request it from the memory. Exploit: Use data from the cache as much as possible. More practicaly: Visit the data only once per <something>. Lets say you develop a game every entity has to update their position and health every turn. You should visit every entity once: "for each entity {update position and update health}" When you update health the data of entity is already in cache. If you do "for each entity {update position} for each entity {update health}" at the start of the second for-loop the first entity will not be in cache anymore (if the cache is not big enough to store all entitys) and another (slow) load/fetch from memory is required. If the CPU fetches data from the memory most of the times it needs an "object" which is bigger than a byte. So the memory sends not only a byte to the cache but also tha data around it. That's called a cacheline. A cacheline is typicaly 64 bytes. Exploit: Place data which is accessed together in the same cache line. If multiple entitys are packed inside the same cacheline you have to do only one fetch to get all entitys in a their. Optimaly the entitys are stored consecutive. If that is not possible an allocator can be used. The yob of an allocator is to place data(entitys) in some smart spot (the same cache line). Allocator can yield gread speed improvement: D4718. Adding "consecutivenes" to an already allocator aware container does also yield a small speed improvement: D4843 Now and then data has to be fetched from the memory. But it would be ideal if the fetch can be started asyncronosly the CPU would invoke the "fetcher"; run some other stuff and the access the prefetched data. Exploit: The compiler should know which data it has to fetch "long" before it is accessed. In an "std::list" one element does store the pointer to the next element. The first element can be prefetched but to get the second element prefetch can not be used. Which data to load can not be determined bevore the frist fetch. Creating a fetch-chain were each fetch depend on a previous fetch. Thus iterating a "std::list" is slower than an "std::vector". Exploit2: Don't use virtual functions they involve a fetch-chain of three fetches. A normal function call does only involve one fetch which can be prefetched and might even be inlined. Back to threading In a single threaded application you might get away with the memory-boundnes. Since big parts of the application fit in to the cache. Using multiple threads each accecing a different part they still have to share the cache and the fetcher-logic(I didn't verify that with measure). The pathfinder is not memory bound (that i did measur) so it yields an improvement. Sometimes i read pyrogenesis is not fast because it is mostly single thraded. I don't think that is true. Yes, threading more part of the engine will yieald a speed up but in the long run reducing memory bound should have bigger priority than using multiple threads. There also might be some synergy between them.1 point
-
merged: https://gitlab.com/0ad/0ad-community-mod-a26/-/merge_requests?scope=all&state=merged closed: https://gitlab.com/0ad/0ad-community-mod-a26/-/merge_requests?scope=all&state=closed1 point
-
See https://mod.io/g/0ad/m/community-mod on the left side there is the changelog1 point
-
Hi @user1, Another player left without resigning when I was winning. It was AlonzoBistro vs. me (MikeyMo) and the game started at 2022-12-19 at 10:42 and he disconnected after 36:22 minutes. I have attached the files. It would be great if you could please add my rating for this win. Thank you in advance. metadata.jsoncommands.txt MikeyMo1 point
-
Dear @user1, blobblob played a 1vs1 one against me (MikeyMo), starting 2022-12-18 at 22:16. After 52:41 minutes he was losing the game and disconnected without resigning. I would like to have the +rating from the game please, it was a well deserved win. Please find attached the required files. Thank you in advance. MikeyMo metadata.json commands.txt1 point
-
@user1 Offender: Hassan_2 Quit rated game without resigning. Please check. commands.txt metadata.json1 point
-
Actually I agree with you because there was some interesting discussion here too.1 point
-
JC, I am aware that a ddoser might do that in order to frame someone. It's why we can't conclude who is a ddoser merely based on potential motive. In fact, it's why in criminal trials, circumstantial evidence is usually not considered. When you see a DDoS, please report as much about it as you can, as explained in the DDoS: See something, say something thread. Mutes in the lobby are not random at all. They are based on violations of the Terms of Use, and always have evidence supporting them. Mute durations increase gradually as violations increase within a 2 week period. Moderators watch chat every few hours, so mutes are often delayed by that much time from the time that the violation(s) occurred. More details are in the FAQ answer about lobby moderation. And, please don't call people "subhuman", even ddosers. Two wrongs don't make a right. Just please help us collect evidence on them and help us improve the software so that it's more costly (in effort, not necessarily money) for ddosers to ddos 0ad players.1 point
-
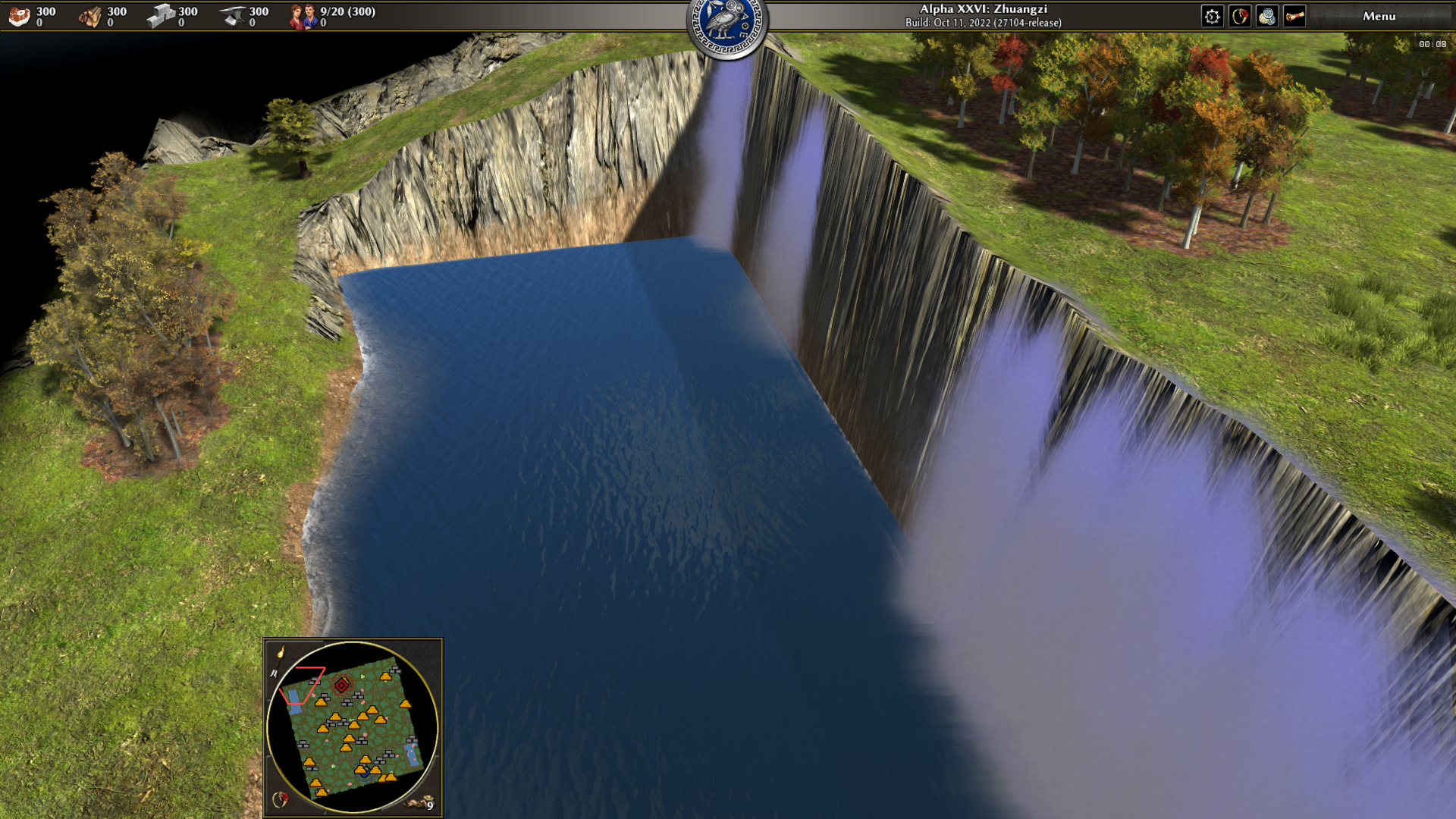
I'm experimenting with particle effects to generate waterfalls on random maps. I'm not super-great with particles or x-y-z things, or numbers, so if anyone wants to collaborate, ping me on PR 74 Video clip
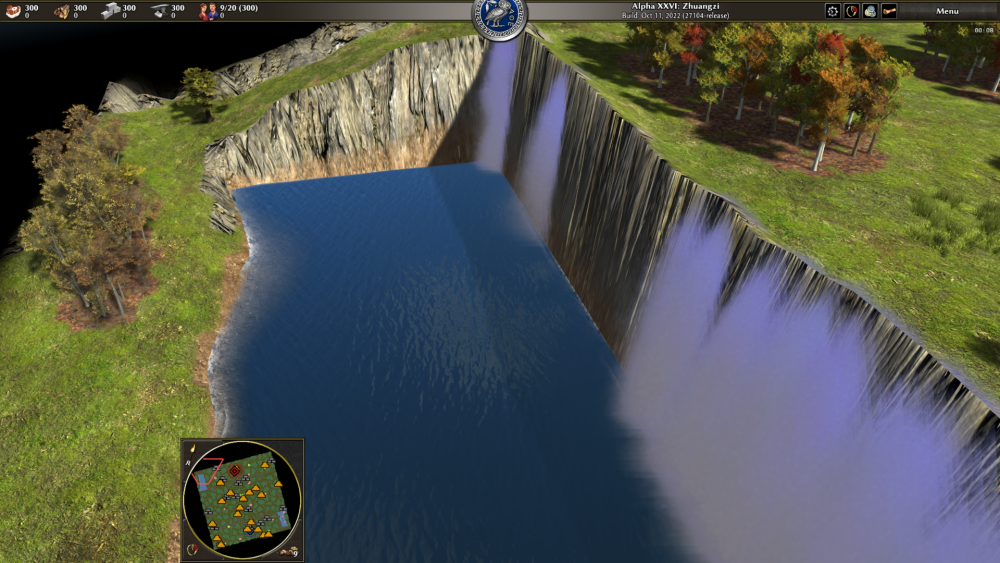 1 point
1 point