Yves
-
Posts
1.135 -
Joined
-
Last visited
-
Days Won
25
Everything posted by Yves
-
I've asked in the newsgroup about the problem with JIT code GC. The different types of functions (loop bodies are another example) and if/how they are protected from GC is something the SpiderMonkey developers have to think about. I'm trying to avoid diving too deep into SpiderMonkey internals. I'm just one person and have enough to do with the interface to 0 A.D..
-
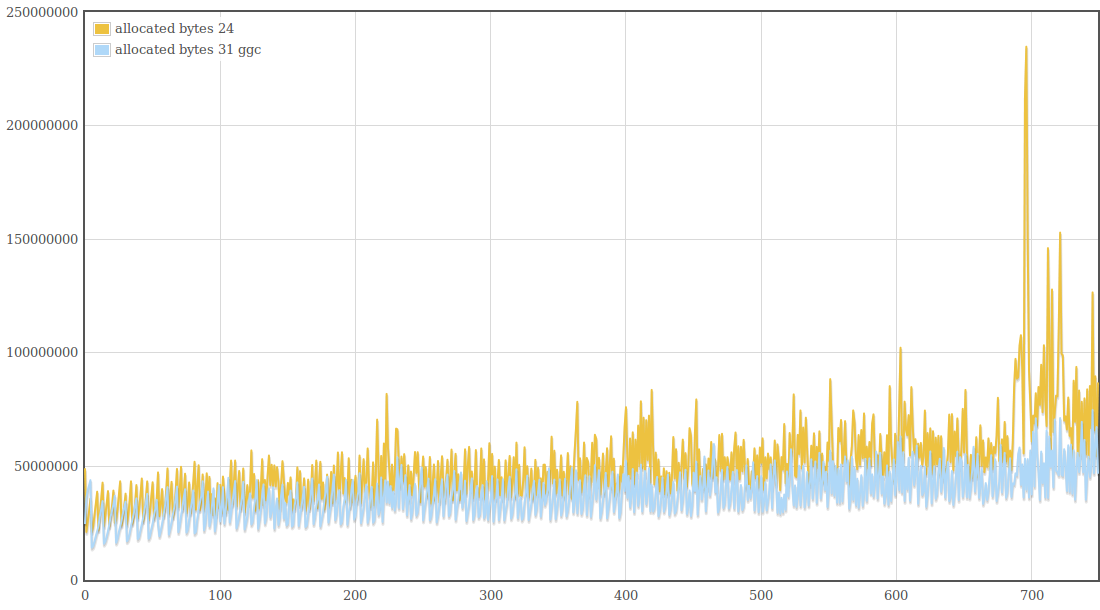
There are two kinds of concerns. The first is that some of our code gets used rarely (like random map code for a specific map or a specific trigger script) and it could cause unnecessary bloat to keep the compiled versions in memory. The other concern is that this setting is meant just for testing and it could have unwanted side-effects like keeping code that isn't accessible anymore. Running one non-visual replay worked quite well though. The memory usage was somewhere between the two graphs of v24 and v31+GGC. I should probably investigate a bit further and ask the SpiderMonkey developers. My concern is that they design the heuristics for keeping JIT code just for the use case of Firefox and not for a case like ours where most of the code should be kept.
-
These graphs definitely not because they only show SpiderMonkey memory usage and SpiderMonkey needs to read the scripts in uncompressed form. I'm not quite sure about how the VFS accesses the rest of the data in the public folder or the ZIP file. It could only make a difference if it loads the ZIP or the folder into memory and extracts the data from there on demand. Jan, a former 0 A.D. developer, spent a lot of work in optimizing the VFS, so I doubt there are any quick wins for performance or memory usage there.
-
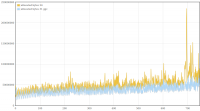
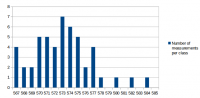
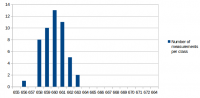
I've made some more performance measurements. I wanted to answer the following questions: 1. What effect does GGC (Generational Garbage Collection) currently have on performance and memory usage 2. What has changed performance-wise since the first measurements in this thread? There have been many changes on 0 A.D., including Philip's performance improvements and AI changes. There have also been some changes in SpiderMonkey since that measurement and in our SpiderMonkey related code. All that could have changed the relative performance improvement directly or indirectly. 3. Have the first measurements been accurate and can they be confirmed again? Based on the experience from the Measurement and statistics thread I suspected that parts of the results could be slightly different if measured again. I didn't expect that difference to be greater than 3% at a maximum, but I wanted to confirm that and get some more accurate numbers by increasing the number of measurements and reducing the effects of other processes running on the system. 4. One mistake I've made in the first measurement was to measure v24 with C++03 and v31 with C++11. I wanted to know how much of the improvement is related to SpiderMonkey and how much to C++11. The measurement conditions were again: r15626, 2vs2 AI game on "Median Oasis (4)", 15008 turns Each measurements was executed 50 times on my notebook by a scirpt (except the v24/C++11 measurement which was executed 100 times). I've posted the distribution graphs just to give a better idea of how close these measurements are in addition to the standard deviation value. SpiderMonkey 24 with C++03 Average: 662.04 s Median: 662 s Standard deviation: 1.68 s Distribution graph of the measured values: SpiderMonkey 24 with C++11 Average: 662.43 s Median: 662 s Standard deviation: 2.47 s Distribution graph of the measured values: It was quite surprising to me that C++11 apparently didn't improve performance at all. At least it didn't get worse either. I have to say that this probably depends on the compiler a lot and I was using a relatively old GCC version which might not be able to take full adavantage of C++11 yet. SpiderMonkey 31, no GGC Average: 661.08 s Median: 661 s Standard deviation: 1.44 s Distribution graph of the measured values: SpiderMonkey 31, GGC Average: 659.94 s Median: 660 s Standard deviation: 1.48 s Distribution graph of the measured values: Memory usage graphs (only from 1 measurement each, comparing v31 and GGC with v24): We see that the average and median values are lower for v31 compared to v24 and for GGC compared to no GGC. However, the difference is so small that it could also be conincidence. That's disappointing because even though the difference in the first measurement was small too, I've hoped for a bigger improvement because of GGC. We don't quite know if the first measurement was conincidence or if some of the changes made the difference smaller again. The memory graphs look quite promising. With GGC there's quite a big decrease in memory usage. Here it's also important to note that this improvement did not have a negative impact on performance. We could have achieved a similar improvement by increasing the garbage collection frequency, but this would have had a bad impact on performance. The additional minor GCs that run between full GCs don't seem to be a performance problem. SpiderMonkey 31, GGC, keepJIT code Average: 572.98 s Median: 573 s Standard deviation: 3.72 s Distribution graph of the measured values (there was probably a background job or something running... the standard deviation is a little bit higher than for the other measurements): So far we have not seen significant performance improvements. Fortunately the impact of SpiderMonkey's problem with garbage collection of JIT code could be confirmed. It's approximately a ~13.5% improvement in this case. There's an additional problem with incremental GC, but I didn't measure that because it's quite hard to setup conditions that reflect the performance of a real fix of this bug. Anyway, "KeepJIT" means I've set the flag "alwaysPreserveCode" in vm/Runtime.cpp from false to true. It causes SpiderMonkey to keep all JIT compiled code instead of collecting it from time to time. Just setting that flag would be kind of a memory leak, so it's only valid for testing. However, SpiderMonkey's behaviour in regard to GC of JIT code has been improved in several changes, so there's a good chance that we'll get a proper fix for that performance problem (unfortunately not with v31).
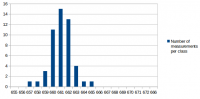
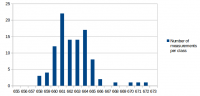
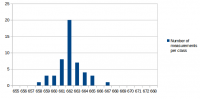
-
I think there's something wrong with the Iberian rams (or all rams?). They can kill a skirmisher in two hits (and probably other units too). They should not even be allowed to attack anything other than buildings. Most of the other changes I've seen seem to be an improvement to me.
-
Or better you have a second computer, then you don't have to touch the first one at all and the results are even better (and you can do whatever you want on your main machine ). I've used my notebook for the measurements.
-
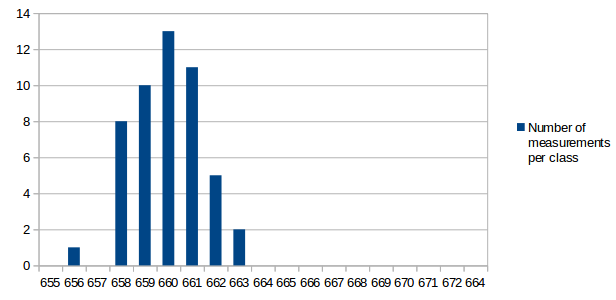
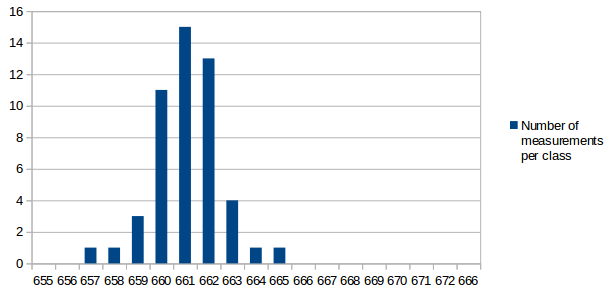
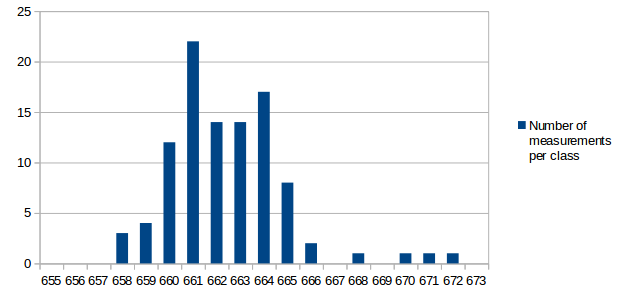
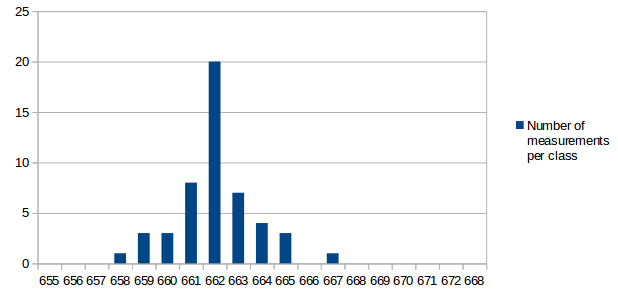
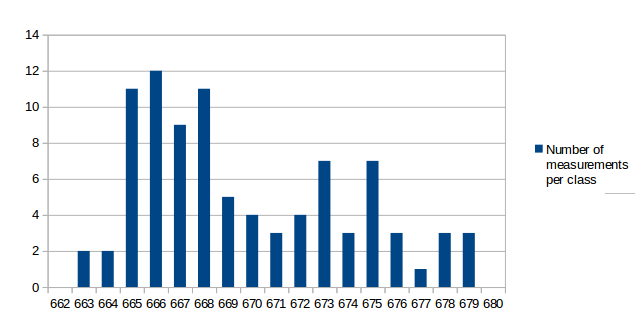
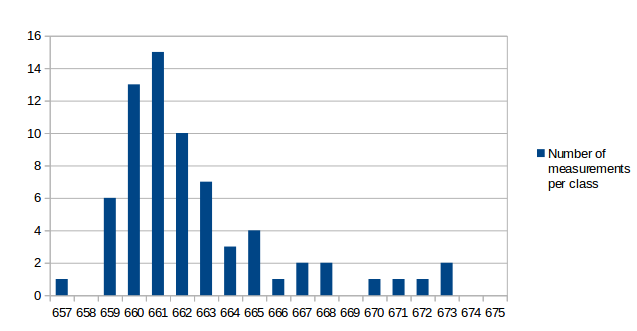
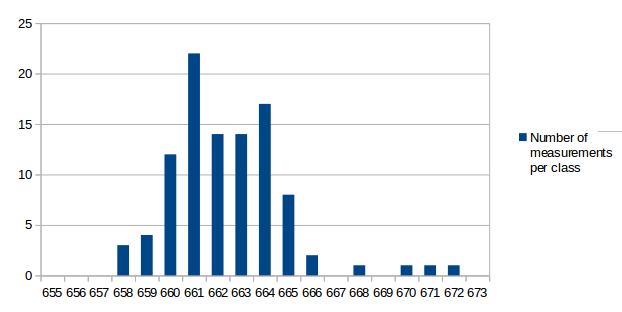
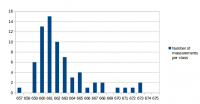
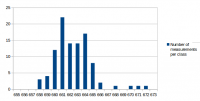
I've analyzed the distribution of the measured values a bit. For all measurements I've used the same conditions as in the first post for the test: r15626, c++11 enabled, 2vs2 AI game on "Median Oasis (4)", 15008 turns First I've assumed that the factors causing differences in the measurements are quite random and that the results will be normally distributed. Such factors are mainly other processes using system resources, delays caused by the hardware and how the available resources are assigned to processes. First measurement series In the first run, I didn't care much about what else was running on my test-machine. I looked at data in the text editor, WLAN was activated and I sometimes even had the resource monitor open. I have a script that repeats the replay 10 times and I ran that script 9 times. The resultant distribution graph doesn't look like a normal distribution: Some statistical data: Average: 669.69 Median: 668.00 Standard deviation: 4.31 Maximum value: 679 Minimum value: 663 Second measurment series I thought that it might increase the accuracy of the measurements if I close all open programs, disable the network and don't touch the computer during the measurement. I've repeated my script 7 times for a total number of 70 measurements. Some statistical data: Average: 662.00 Median: 661.50 Standard deviation: 2.79 Maximum value: 676 Minimum value: 657 As you can see, the data is grouped closer together and has a better tendency to a central value. These are indications that the measured data is indeed more reliable. Third measurement series The first and second measurement had produced quite different Avarage and Median values. It was a difference of around 1%, which means that performance improvements in that scale could not be reliably proven. I wanted to know how close a third measurement would get to the second when using the improved measurement setup like in the second series. This time I've just set the number of replay repetitions to 100 in the script instead of running the script 10 times. Theoretically that's the same and unless my CPU catches fire, it should also be the same in practice. Some statistical data: Average: 662.43 Median: 662.00 Standard deviation: 2.47 Maximum value: 672 Minimum value: 658 The results are very close to those of the second measurement series. Conclusions: For measurements with maximum accuracy, it makes an inportant difference to reduce the number of running processes that could influence performance of the system. Especially on the graphs, it's very obvious that there are still some outliers. For this reason I would say that the median is the better value to compare than the arithmetic mean (average), although it seems to make a small difference here. About the distribution I would say that it is similar to normal distribution, but it's not true normal distribution. Generally there are more outliers on the right side and the curve goes down less steep on the right side. That's probably because there's a theoretical minimum limit of how many processor cycles, memory acces operations etc. are required. Going below this limit is not possible, but it can always go higher when some other processes on the system disturb the measurement. The data is attached as csv file if you're interested to play around with it. Data.txt
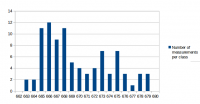
-
That's not quite true. The game does stuff in multiple threads for random map generation, sound, some network related tasks and the user feedback functionality on the main menu. SpiderMonkey, our Javascript engine, runs JIT compiling of Javascript code in separate threads and some parts of the garbage collection happen off-thread. Saying the game is completely "single threaded" is technically wrong and just means that some very performance intensive tasks that could benefit from multithreading don't do it yet.
-
I'm reading a book about statistics at the moment. I expect this to be useful when measuring and comparing performance, especially in cases where the results vary a lot between multiple measurements. I'm posting my conclusions here because I'm not very confident that they are correct and would be glad about some feedback. So for trying it in practice, I've made multiple performance measurements. They were all with r15626 and c++11 enabled. It was from a 2vs2 AI game on "Median Oasis (4)" over 15008 turns. The values are the number of seconds it took to complete the whole replay in non-visual replay mode (-replay flag). I've made the same test 10 times. 665, 673, 675, 669, 666, 668, 668, 678, 679, 667The average value is 670.80. That value alone doesn't tell us how much different measurements vary, so we also need the standard deviation, which is 5.07. This still doesn't tell us how reliable the result is. Would it be possible that we measure another time and suddenly get a value of 800? Based on my experience with this kind of measurement I can say that this is very unlikely, but how can this be proven with statistics? This can be done by calculating the confidence interval for the average. We start by calculating the standard error of the average value : s = standard deviationn = numbersm = standard errorsm = s/sqrt(n) = 5.07 / sqrt(10) = 1.06Now to calculate the confidence interval, we have this formula (t-table here): m = averaget = t-value in the t-table for df = n-1 and using .0.05 in the "α (2 tail)" column.0.05 stands for 95% probability.u = universe average (I hope that is the right term in English)--> m - t * sm < u < m + t * sm--> 670.80 - 2.262 * 1.06 < u < 670.80 + 2.262 * 1.06--> 668.40 < u < 673.20So we've chosen the t-value for 0.05. This means if we repeat the test, the average value will be between 668.40 and 673.20 with a probability of 95%. I'm uncertain about normal distribution. The t-test requires normal distribution of values and I assume that the measured values aren't necessariliy normal distributed. I'm also not sure if the central limit theorem applies here because we are working with an average value. Any thoughts?
-
We have a description in the wiki: http://trac.wildfiregames.com/wiki/Manual_SettingUpAGame#HostingJoiningaMultiplayergame
-
I'm currently the only one working on the SpiderMonkey upgrade and I'm not at school at the moment, so that shouldn't be a problem. There will probably be a project at work which will require a lot of time soon, but there have been other projects in the past and I should still have enough time to complete the upgrade for Alpha 18.
-
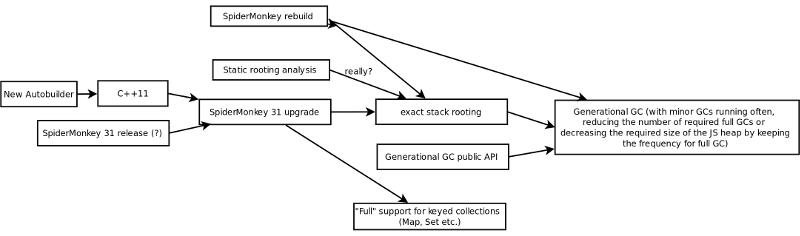
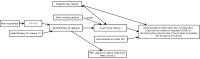
The currently planned schedule needs replanning. We have several options for the upgrade and related tasks and need to decide on the priorities. Unfortunately, the two major bugs (bug 991820, bug 984537) have not yet been fixed or not in time for v31. This means the performance improvement of the upgrade won't be as big as the best results in the first post of this thread (nearly 20% simulation performance), but if the first measurements are still valid, it should still be nearly 10%. These numbers are only valid for that specific testcase and can be different in other cases of course. I was hoping that generational GC could mitigate the impact of these bugs, but the public API is not quite ready to control generational GC yet and I haven't yet tested if it really helps. I wanted to get ready with exact stack rooting support (ticket #2415) before the upgrade because it needs a rebuild of SpiderMonkey with different flags (and new Windows binaries). It would also be good if our programmers get used to exact rooting now. Most of the changes for exact stack rooting are done, but there's still quite a bit left. Especially it needs careful testing. We have to test specifically for that because rooting issues are very hard to find by just playing the game. The same thing could work a thousand times and then suddenly fail because of garbage collection timing. There's dynamic rooting analysis which can already be used and we might also need static rooting analysis, which is probably quite a bit of work to implement (ticket #2729). I still don't know enough to tell if we really need the static analysis though. The SpiderMonkey 31 upgrade itself (without all the additional things like rooting) is a bit behind schedule. I haven't heard of any progress from Philip on the autobuilder (which we need for C++11 and SpiderMonkey) and I noticed that there's no bundled release from Mozilla yet. In addition there's still some work I have to do on the code. After all this is done, a testing period of at least one week is needed. I don't think this is all going to happen in less than two weeks (until the currently planned Alpha 17 release). I would reduce it to two options now: We aim for Alpha 17. In this case we'd probably keep exact rooting disabled but would continue with the API transition. Developers could also enable it if they want and don't mind rebuilding SpiderMonkey. This also depends a lot on Philip and whether he can/wants to complete the autobuilder work in time. The Alpha 17 release would most likely get delayed. We would have a small performance improvement. We plan the upgrade for after the Alpha 17 release. In this case we have more time for the autobuilder and exact rooting and it could be committed with exact rooting already enabled. Most of the benefits from exact rooting won't be accessible before the next SpiderMonkey version, but it would still help a bit. Some JIT compiler bugs were related to the conservative stack scanner for example. I haven't yet done performance tests with only exact rooting enabled.Here's a little visualization of the dependencies:
-
The size of the stairs looks quite different in these two buildings.
-
Instead of "c" for "continue" you should type "bt" for "backtrace". You might also need to install the 0ad-dbg package to make the output of "bt" useful. The output should contain some function names and not just a bunch of addresses.
-
source: http://fridge.ubuntu.com/2014/04/17/ubuntu-14-04-trusty-tahr-released/
-
Das erste Video hat mir gut gefallen, weiter so! Du hast das richtig bemerkt, beim Wechseln der Karte werden auch die ausgewählten Völker, die KI-Gegner und deren Schwierigkeitsgrad zurückgesetzt.
-
I wouldn't worry about supporting Windows XP, not even Microsoft supports it any more. With the rest I agree.
-
That alone would definitely not be worth the change. I shouldn't have listed that first, the order of pro and contra points in the ticket is completely random.
-
This thread is for discussions and opinions about the C++11 migration. The ticket (2669) should be used for documenting facts, decisions and tasks. My personal opinion is that we should make the move now. Because it's just a matter of time, most of the contra arguments don't really matter. It's better to get used to the new coding style early. Also I'd like to continue with my work on SpiderMonkey and not doing the migration would interrupt that abruptly. I'm not happy that a third party library puts pressure on us this way, but it's a question of what alternatives we have. Staying on V24 would be bad and switching to another scripting engine or even another script language like Lua has been discussed and discarded before.
-
[FALSE POSITIVE] Build: May 11, 2014 (15145) virus/malware/etc problems..
Yves replied to Schwanke's topic in Bug reports
You can always check the MD5 checksum of the download to make sure it didn't get compromised or damaged during download or on the download server. The checksum for the Windows download of Alpha 16 should be "00a143c354fa4c19f64f71de9dc7f1b5". -
I'm looking forward to many beautiful, exciting and creative maps! Well done organizing the contest!
-
Yes, more or less if you mean this one. You can see "authored 18 hours ago" at the moment and here you see the commit history (taken from SVN).
-
Hmm I've seen units doing that with the current implementation, but I don't know if it's caused by the pathfinder.
-
[RESOLVED] Unable to build cause of spidermonkey [faulty RAM module]
Yves replied to Clovisnox's topic in Help & Feedback
Was there a compiler update recently? As far as I understand the compiler crashes, so it must be a bug in the compiler or in a system library the compiler uses. -
Build environment and deployment on the Mac
Yves replied to Yves's topic in Game Development & Technical Discussion
Type_traits is c++11 related. Try experimenting with these flags or wait if one of our Mac developers responds. -std=c++11 -stdlib=libc++