

RedFox
-
Posts
245 -
Joined
-
Last visited
-
Days Won
7
Posts posted by RedFox
-
-
Awesome post, you got to doing this before I could!!! The scary thing is that this is before a game has even started.
Well, sadly the application doesn't handle memory very well itself and crashes when I try to profile after loading a map.
If you have a 64-bit OS with more than 4GB of ram, you could perhaps post profile information of an actual game in progress?
-
@Thanduel: Using memory analyzer from http://blog.makingar...com/?page_id=72, run 0ad with it in debug mode , switch to "fragmentation tab" and you'll have nice memory mapping block drawings showing just that.
(other tabs still interesting, should be able to spot all the recurring "allocators" code spot, and all the other memory problems)
Wow! This is an amazing tool! Plus rep, man!
 You're now my personal hero, really, for finding this awesome tool.
You're now my personal hero, really, for finding this awesome tool.First test:
Pyrogenesis rev #13491, Release, VC++ 2012
Only Main Menu (lets start it slow)
The first thing that makes leak detection really hard is the GC due to the constant memory increase and free cycles.

Next stop is to analyze the first heap, which is the mozilla js engine heap.
A note about the fragmentation graph: Red blocks represent allocated nodes, white blocks represent free nodes AND memory node headers. I don't know why they didn't exclude those headers, since it makes finding frags very hard.
The slightly larger white blocks between red blocks are fragmentations.
The js heap could be described by a very large amount of small allocs that are luckily rounded off to 32byte alignments. This greatly reduces fragmentation, though there still is quite a bit of it. What should be considered again is that this is just the 'quiet' main menu.

Next is the CRT heap, the heap used by C, C++ and pretty much every other library. This is the most important heap of the program. What could describe this heap is:
1) Lots of tiny allocations - This is bad for malloc/free speed since there is a lot of coalescing going on.
2) Fragmentation - This is bad for malloc speed since these nodes are in the freed list, meaning malloc has to iterate through them every single time, making it gradually slower. In this case the smaller nodes are the main culprits - the bigger blocks can be broken down and used, but the small ones stay in the freed list.


Now if we look at the distribution of allocations during the entire long run of the main menu, we can notice that most allocations are aligned to neat 8-byte boundaries, which makes them easy to manage. However, the sheer volume of same-sized allocations is staggering.

There are two ways to increase general performance:
1) Localized usage of custom pool allocators - This is hard to achieve across the entire program, but Arena allocators are nothing new. And it's fast.
2) Use jemalloc - This is basically a collection of thread local Arena allocators sorted into bins and is superior to dlmalloc (http://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf). It's probably the fastest general purpose solution you can think of and it has seen years of debugging.
Writing a custom pool allocator is surprisingly easy, BUT jemalloc uses VirtualAlloc / mmap to expand its pools by mapping more virtual addresses to the end of the memory block, which is the most efficient way out there.
Of course, to get the speed-up of releasing a whole bunch of nodes in a single go, you'd still need to use a memory pool.
I'll post a sample of memory allocation during actual gameplay later.
-
 1
1
-
-
Please elaborate on this. I understood the oct- or quadtree would be functioning as a sparse array, with a single cell at (x,y,z) corresponding to one leaf node in the tree and one "game object." But you make it sound as if you'd like to be able to subdivide the space further at runtime.
Each Quadtree/Octree node should have a predefine attribute 'MaxObjects', which can be, for example 4. If the number of objects per node grows larger than that, the node is sub-divided into 4 cells. This is known as an 'adaptive Quadtree/Octree'. Typically it performs better due to less Nodes.
An unadaptive Quadtree/Octree works by dividing up to 'max levels'. This may or may not work better, depending on the nature of data. For a collision/range Quadtree of units, an adaptive Quadtree would work better in cases where a lot of units are in a very small area. Whereas an unadaptive Quadtree would have better tree performance, but suffers if you have a lot of units in a small area.
As for actual nodes themselves, they can be anything, really. For example they can be Entity structures that contain 3D position data. That's why you can calculate the correct ranges in 3 dimensions with a Quadtree and why we'd never need an Octree.
-
Thanks for the awesome discussion everyone, a lot of important points have already been mentioned.
First of all, Launchpad looks really awesome. I wonder how difficult it would be to integrate it into the current development cycle?
@RedFox: If it's set in stone that you want to use your "dictionary" approach you can still use all the gettext utilities. You just have to create a POT file by collecting all translatable strings (however you want),
Since we can use .MO files, the plain text is starting to loose its point. Binary is always a more preferred format for sure. As for creating a POT file, we can use the wfgpotext program to just cycle through all the current XML files and generate an appropriate POT file from the texts in those files.
I guess I had a slightly different idea of collating the source text files into text files like (en_gui.txt, en_units.txt, etc.). And for mods that added new units, they could just create a "en_mymod.txt" file in their mod folder. It would also be trivial to update these entries with an 'Entity editor' of some sort.
I still doubt you get any benefit from your format as i also think string handling isn't a bottleneck.
I guess the plaintext format was never really the main point - the neat sideffect of having to only do 1 malloc for the entire thing was the point. Also avoiding any temporary std::string objects.
Even though a small part of the game such as this doesn't seem like it has a big effect (or any effect), we should accept that all of these different modules across the 0 A.D. source add up to a butterfly effect.
Creating a huge amount of string objects early on will definitely fragment memory - it's an accepted fact and has made clever developers even use temporary heaps when they have to do a large amount of string operations in programs with a long life-cycle. If you trash the heap with strings you'll make further allocations slower and some memory will be lost due to fragmentation.
Now if you add all this up to a large scale project like 0 A.D. with all its different modules that "don't care about memory", you'll get your desired butterfly effect and you'll see the game eat up more and more resources. I'm just saying game development has always been about clever tricks to squeeze out the best from the CPU. This is not just some business app where you don't care about performance - you'd use Java, C# or even Ruby for that.
Even though we know there are the 'big obvious bottlenecks', we should also not underestimate tiny objects that fragment the heap. Those not familiar with memory fragmentation should read up: http://blogs.msdn.co...-and-wow64.aspx
Even though your program seems to not take that much memory, the allocations can get slower and slower over time, because it becomes increasingly more difficult to find a reasonably sized free block.
I'm sure though that a similar low-fragmentation approach can be used for .MO files, so that would be a preferred solution. For all intents and purposes, the strings can remain in entity description files as they are now. And we can generate .POT file based on those XML files. Then the translators can jump in and do their magic.
-
How would the translated .po or .txt be committed to SVN, if not by copying it from the translator? Would they send their entire harddrive by carrier pigeon?

Haha
Yeah. I'm afraid you can't avoid having to copy some files if you're working on a project... 
-
What data would you cache?
A cached text collection can just be a binary array. The first 4 bytes would be the 'length' of the array, followed by the data. We don't actually need to store the string lengths, but we could do it to save some processing time for the CPU. Also, if we store entries with an 'idhash' we somewhat loose the point of having a visible 'id string', but we should store it anyways, because the debugging info might be useful to us later.
First it would require a redesign of the TEntry structure:
// Describes a TEntry shallow UTF-8 string reference
struct RefStr { unsigned short len; const char* str; };
// UTF-8 Translation Entry
struct TEntry
{
RefStr idstring; // 'id string' of this entry
RefStr generic; // 'generic' attribute string
RefStr specific; // 'specific' attribute string
RefStr tooltip; // 'tooltip' attribute string
RefStr history; // 'history' attribute string
};Now we need a binary version of TEntry that is more compact and also contains the 'id hash'. We'll store the strings using the same layout as a TEntry, to make them compatible (this will be useful later...). This also means that the pointers in the RefStr structures will be garbage and need to be recalculated when a BTEntry is being loaded:
// Binary UTF-8 Translation Entry
struct BTEntry
{
size_t idhash; // 'id hash' of this entry
RefStr idstring; // .str = data
RefStr generic; // .str = idstring.str + idstring.len + 1
RefStr specific; // .str = generic.str + generic.len + 1
RefStr tooltip; // .str = specific.str + specific.len + 1
RefStr history; // .str = tooltip.str + tooltip.len + 1
char data[];
};We can then load all of the binary entries in one swoop. This implementation is a lot more efficient since the storage for TEntry structures is in the loaded binary file itself. If you'd want to make this even more efficient you can insert a binary search table in the header of the file. As for having to recalculate the strings.. It would probably be better if the string pointers were saved as offsets from data instead...
void LoadEntries(FILE* f)
{
// put it here for the sake of this example:
std::unordered_map<size_t, TEntry*> entries;
fseek(f, 0, SEEK_END); size_t fsize = ftell(f); fseek(f, 0, SEEK_SET);
size_t* mem = (size_t*)malloc(fsize);
fread(mem, fsize, 1, f);
size_t numEntries = mem[0];
BTEntry* bte = (BTEntry*)(mem + 1);
for(size_t i = 0; i < numEntries; i++)
{
size_t offset = 0;
auto fixptr = [&](RefStr& rs) {
if(rs.len) {
rs.str = bte->data + offset; // update the string
offset += rs.len + 1; // update offset
} else rs.str = nullptr; // we don't have this string
};
fixptr(bte->idstring);
fixptr(bte->generic);
fixptr(bte->specific);
fixptr(bte->tooltip);
fixptr(bte->history);
// convert BTEntry to a TEntry pointer by skipping the hash
entries[bte->idhash] = (TEntry*)&bte->idstring;
// next chunk
bte = (BTEntry*)(bte->data + offset);
}
}I can't readily imagine what the process would be. Copying the POs back and forth manually? As long as I don't have to do it, I guess I can't stop you
Wouldn't really have to copy anything. A single batch script can run wfgpotext to generate a new POT template for anyone who wants to do translation. Those PO files can be easily converted back to .TXT. Heck, I should just edit wfgpotext to run the whole life-cycle, updating PO templates and text files in a single go.
It would need to:
1) Generate PO Templates from TXT files:
en-US_{0}.txt => wfg_{0}.pot
2) PO translations to TXT:
{0}_{1}.po => {0}_{1}.txt
3) Make sure en-US_{0} is never overwritten, since they're our baseline. That would be sad indeed.
-
Not really. As you said, it would still be slower than binary.
Ahh, not that. I mean on-the-fly caching would be very easy to do with the text system.
If we make it excessively hard, obviously they won't. The end result will just be undermaintained and unfinished translations.
You are right about that. We can however provide the necessary .PO files for anyone who wants to translate the game text, right? That would give us the benefit of keeping the game strings easy to mod and easy to translate.
In any case the game strings should be collated to text files like en-US_units.txt, since in the end it makes modding the visual name of an entity very easy.
-
If we use caching on-the-fly conversion from text to binary, it would still be moddable. (Regardless of which 'catalog' format is selected.) Though I suppose that would not be compatible with tinygettext.
But it would work perfectly with the text dictionary system, no?
I think we should provide the tools to integrate .po (wfgpotext.exe), but the game itself shouldn't rely on it. We don't need yet another third party library that somewhat does what we need if we squeeze hard enough. In the end, the amount of code for the text dictionary is still 150 lines, which is maintainable enough.
Most people won't end up using fancy translation software, but in the case they want to, we'll have the PO Template for them and the tool that convert it back to .txt.
-
I wasn't referring so much to the format of the file as to its contents. POs are normally converted to the binary MO format anyway, which is more tightly packed than the format you are suggesting.
You are right in that. Binary format would win in any case.
Did you notice how much functionality you are throwing out by using the allegedly simpler custom format? I'm just trying to point out that the options seem to be either something on the level of complexity I suggested, the IMO strongly neutered format you suggested, or standard PO. I would prefer the latter, but it's always a good idea to at least take note of the alternatives.
I agree that it's neutered; the whole point was to have simple-to-edit text files so that anyone could jump in and edit whatever they wanted without having to use anything more complex than perhaps Notepad.
You forget about your id strings/keywords which you have to load from the xml files. So basically the amount of allocations is only 1/3 because you merged generic, specific and history into one keyword.
The amount of allocations for strings is only 1: the buffer for the text file. An entity won't reference any hashes or id strings once it has loaded a translation entry pointer.
The only real difference with your approach is you do this string pooling for the english messages too.
Yes, which is the point of it.
The lookup and the message catalog are highly optimized in gnu gettext. It hashes the string and looks it up in the message catalog which is by default a MO file[1]. It also caches results[2]. I wouldn't be surprised if the whole catalog is memory-mapped, but i'm not sure about it (looking at strace it sure looks like it).
Now that's something different. Having a binary file would be the fastest way to do this, but it would also mean you can't jump in and edit the game texts as you go. The goal is to be able to translate the strings with or without a third party tool (I'll get back to you on the 'with' part).
-------------------
I've been working on a small command line tool that allows .TXT to .POT conversion and .PO to .TXT conversion. It's written in C# 2.0, so you'll need Mono 2.0 or .NET 2.0 to run it.
Usage:
-? --help Shows this usage text
-o --overwrite Forces overwrite of an existing file
-p --pot <src> <dst> Converts TXT to POT
-t --txt <src> <dst> Converts PO to TXT
Converting TXT to POT:
wfgpotext -o -p en-US_units.txt wfg_units.pot
Converting PO to TXT:
wfgpotext -o -t de_units.po de_units.txtGiven a base input translation file: en-US_test.txt:
;; Generated by WFGLocalizationConverter
army_mace_hero_alexander
generic Army of Alexander the Great.
specific Army of Alexander the Great
tooltip This is what an army would look like on the Strat Map.
history The most powerful hero of them all - son of Philip II.We run the .TXT -> .POT command:
wfgpotext -o -p data/en-US_test.txt wfg_test.potThis will generate a .pot template file. You can use this file to keep track of string changes with your favorite .PO editing software.
# POT Generated by wfgpotext
msgid ""
msgstr ""
"Project-Id-Version: \n"
"POT-Creation-Date: \n"
"PO-Revision-Date: \n"
"Last-Translator: \n"
"Language-Team: \n"
"MIME-Version: 1.0\n"
"Content-Type: text/plain; charset=utf-8\n"
"Content-Transfer-Encoding: 8bit\n"
#
#: data/en-US_test.txt:4
msgctxt "army_mace_hero_alexander_generic"
msgid "Army of Alexander the Great."
msgstr ""
#
#: data/en-US_test.txt:5
msgctxt "army_mace_hero_alexander_specific"
msgid "Army of Alexander the Great"
msgstr ""
#
#: data/en-US_test.txt:6
msgctxt "army_mace_hero_alexander_tooltip"
msgid "This is what an army would look like on the Strat Map."
msgstr ""
#
#: data/en-US_test.txt:7
msgctxt "army_mace_hero_alexander_history"
msgid "The most powerful hero of them all - son of Philip II."
msgstr ""An example translatio with Poedit. Imported wfg_test.pot, translated and saved as ee_test.po:

ee_test.po:
# POT Generated by wfgpotext
msgid ""
msgstr ""
"Project-Id-Version: \n"
"POT-Creation-Date: \n"
"PO-Revision-Date: \n"
"Last-Translator: \n"
"Language-Team: \n"
"MIME-Version: 1.0\n"
"Content-Type: text/plain; charset=utf-8\n"
"Content-Transfer-Encoding: 8bit\n"
"X-Generator: Poedit 1.5.5\n"
#
#: data/en-US_test.txt:4
msgctxt "army_mace_hero_alexander_generic"
msgid "Army of Alexander the Great."
msgstr "Aleksander Suure armee"
#
#: data/en-US_test.txt:5
msgctxt "army_mace_hero_alexander_specific"
msgid "Army of Alexander the Great"
msgstr "Aleksander Suure armee"
#
#: data/en-US_test.txt:6
msgctxt "army_mace_hero_alexander_tooltip"
msgid "This is what an army would look like on the Strat Map."
msgstr "Armee näeb Strat Kaardil selline välja."
#
#: data/en-US_test.txt:7
msgctxt "army_mace_hero_alexander_history"
msgid "The most powerful hero of them all - son of Philip II."
msgstr "Kõigist võimsam kangelane - Philippos II poeg."Now to get the translation back to .txt, I'll have to call the conversion tool again:
wfgpotext -o -t data/ee_test.po ee_test.txtAnd the resulting translation text file:
; Translation file generated from ee_test.po
army_mace_hero_alexander
generic Aleksander Suure armee
specific Aleksander Suure armee
tooltip Armee näeb Strat Kaardil selline välja.
history Kõigist võimsam kangelane - Philippos II poeg.You can test out the tool and check the generated files from the attached archive:
-
If this is a concern, can't we include the POT file* in the game data, which can then be loaded "in one go" into a map at startup;
You could, yes, but POT and PO files have a much more extra data. The idea of a simple text file is to have minimal amounts of garbage text. This way, loading the file in one go makes much more sense since the text is tightly packed.
when a game string is later found in an XML file, the string is translated into an address in the map, which is stored in the appropriate data structure in memory; this address can then be used to lookup the string to invoke gettext on. Won't that accomplish the same thing?
If I understand you correctly, it seems to be more of a concern with how gettext is invoked than with gettext itself.
(* The POT file is a collection of all the source strings that have been marked for translation in the source code and data.)
Did you notice how complicated what you suggest, is? Lets break it down:
Gettext load .po;
Load entity XML -> Translation String -> Hash;
Invoke gettext -> translation string hash -> get translated string;
Store (create copy) translated string in map using the original Hash.
It's basically a search and replace method using gettext. That goes through sooooo many layers its not funny. What I proposed was:
Load lang txt
Load entity XML -> Get id string -> Hash;
Invoke dictionary -> Return TEntry;
It's very simple and very straightforward. Even the C++ code for it is tiny.
Does it accomplish the same thing?:
No, the whole mechanics differ and the amount of 'memory pressure' is several magnitudes higher for the gettext version. A good analogy might be texture mipmaps: if you use a mipmapped format (for example .dds), you only have to load the texture from the file and write it to vram. If you use a non-mipmapped format, you'll have to generate the mipmaps on-the-go, which is several times slower, depending on the actual texture size. This is a very noticeable performance difference in games development.
The same could apply here. Using the dictionary txt format, you'll only have to load the file once and you'll have your translated strings. The gettext method inherently requires creation of temporary strings and has an additional layer of 'search & replace' complexity.
-
But then again they have to know the intented meaning of the keyword and where it is shown ingame. Isn't your data laid out badly if the information is too fragmented? Better merge some data files than collecting it later.
I don't really get what you want with your dictionary (string pool?). It doesn't make sense for english if the english text is in the source or data files.
Regarding the 'dictionary' and how it works. You use an id string to define a single translation entry:
;; en-US_units.txt
athen_champion_marine
generic Athenian Marine
specific Épibastēs Athēnaïkós
history .Now in the entity templates section you use the id string as a reference to the defined translation entry:
<Entity ...>
<Identity>
<TranslationEntry>athen_champion_marine</TranslationEntry>
</Identity>
</Entity>In order to translate your unit, you'll just generate a new language file 'de_units.txt'. Also notice how I don't have to redefine the 'special' name, since its already defined in 'en-US_units.txt':
;; de_units.txt
athen_champion_marine
generic Athener Marine
history .In this case the information is not fragmented at all. If you add the text into your Entity descriptions, then that creates the fragmentation. You could look at it both ways, but ultimately, using a collated text file for the translations is a neat way to keep track of your game strings without spreading them out all over the code.
You already parsed the xml and hold the information in some object. Why do another lookup in a dictionary? For other languages where you have to translate, gettext of course uses a hashmap. So there you have your dictionary.
If you took a closer look at the code snippet I posted, you can see that it loads the entire translation file and tokenizes it in-place. This means only 1 allocation and a fast tokenization of the data. The addresses of those tokenized strings are put into TEntry structures, which are put into a hashmap. There are no string allocations.
During unit initialization you'll only have to reference the dictionary once (you usually don't change game language during runtime):
Entity* e = Entity::FromFile("athen_champion_marine.xml");
// behind the scenes: e::Descr = unit_dictionary["athen_champion_marine"];
printf("%s", e->Descr->generic); // output: "Athenian Marine"Regardless of any lookups, there are yet again two gains for this method:
1) All game text is collated into specific text files. If you are new to the project, you can easily edit a name by opening up the text file and hitting Ctrl+F for your unit name. No need to go looking through tons of templates.
2) Due to the simplicity of this method, all the text can be loaded in one go and you don't need to create a separate std::string object for each game string. You avoid memory fragmentation this way (which is the main point). String objects are notorious for fragmenting memory.
-
You'd face multiple problems by implementing your own system.
You are using a keyword based system which is bad for the translators. Just look at the examples posted by historic_bruno: You have to translate some arbitrary keyword which means you have to lookup first the english "translation" to get its meaning and then translate. It's also bad for the developers as they now have to look at two places: The source code where the keyword is used and the english translation.
Why not just use the english phrases in the source code and extract it from there (as is the case now anyway)? The developers just have to maintain the source code and the translators get an english phrase or real word to work with. That's what gettext does.
How do you do updates? How do you inform other translators that the english translation of a keyword changed? What do you do with old obsolet/unmaintained translations? How do you inform translators about new keywords? You'd have to write tools for all these situations and probably more (like context and plural). Gettext and PO-editors have all these features already.
And i just have to second zoot. PO files are text files. If you don't want to use a PO-editor with nice comfort functions or an online translations system like transifex then just use a plain text editor.
Think of the historians, too. The people who actually have to write all the English text of the game - it's a lot harder to change a bunch of visible names if they're spread out across multiple files. In this case having a central file that contains all the text is both logical and efficient. Having the text spread out between files also implicates string fragmentation in memory - there is no efficient way of creating an actual dictionary this way - you'll be forced to fragment memory.
AAA games use systems like this due to performance implications. Performance has long been a bottleneck of 0 A.D., so why do we insist on implementing non-standard (in context of the gaming industry, not gnu applications) methods? Take a look at any AAA game like Mass Effect, Total War - Shogun 2, Skyrim, Battlefield 3 - they all use a dictionary system (if you don't believe me, just check their game files yourself). It works and it's efficient.
Writing a system that generates .po files from these .txt files isn't hard. It can even detect updated strings by cross-referencing old and new dictionary. IMHO a tool can be used that generates a .po file for translation and then back to .txt - the game strings themselves should remain in collated .txt files.
Hello.
I just want to chime in that I vote for the existing method of translation, namely the po file. Beside saving you the added work of making our own solution, po files and po editors are great ways to translate software with advanced features and easy to use.
I did some translating for The Battle for Wesnoth game in the past, and I can say that the po file translation have many advantages:
1. Source comment: The developers can use comments to inform translators about the context of the string they are translating. Translators can use comments to indirectly communicate with each other about the translation.
2. Translation memory: Po file editor allows you to create "translation memory" with the source language and its translation. The editor will memorize your translation and if a non-translated string matchs its memory, it will suggest you the relevant translation. This means greatly to translators as they can agree on the correct words to use in various strings for a more standardized and consistent translation.
3. Efficient update: When a new language file comes out, it's easy to update the translation. The editor will automatically add the new strings and remove obseleted ones, allow a more up-to-date translation in tandem with translation memory.
4. Simplification: I'm not a developer myself so I can't quite talk about this but a lot of errors come from the translator having to work with the source, po files eliminates this problem (mostly).
In conclusion, po files will save the developers and translators alot of works. Do use it please
Regards,
snwl
Since using .po files for the text editors is becoming a very strong argument, I could develop tools that handle the intermedia .txt -> .po conversion and .po -> .txt.
I'll just try to address each of your argument and see how this could be tied with .txt -> .po, .po -> .txt converter.
1) Source comment: The dictionary text files have comments, so this is not an issue
2) Translation memory: Comparing which strings have changed is nothing difficult. It just requires we keep a previous .po file for comparison. So if a new .po file is generated, it can be compared to the old one.
3) Efficient update: If we stick to the .txt -> .po conversion this shouldn't be an issue.
4) Simplification: In this case the dictionary .txt files a very simple, so it's difficult to make any errors. At any rate, C-style format strings should not be used inside translation strings - that's just bad design.
In all sense, .po format indeed has its upsides and since so many editors already exist for them it makes sense to use that format. In my opinion the best middle-ground solution to gain the benefit of both systems would be to:
1) Use dictionary .txt for the game strings
2) Have a tool that can convert .txt to .po
3) Have the same tool also convert .po back to .txt
I'll update the post later on with this new tool.
-
That seems mostly to deal with entity templates, which are certainly one part of the translation issue, but not all. We'd still have to come up with custom solutions for JS, JSON, and GUI XML? Personally I'm leaning toward the approach taken on http://trac.wildfire...s.com/ticket/67 that uses existing libraries, tools, and data formats. I don't have experience translating software, but if someone who does says that's a common approach, it's a major consideration. If the tools are out there to do what we want, why reinvent the wheel?
Indeed it only considers entity templates for now, but also adding GUI localization conversion would be trivial. C# is perfect for these little conversion tools; it took me around 30 minutes to throw together that program.
I think the first concern of Michael was that most modders are not familiar with translation software and thus, for the sake of moddability, a clear and simple file would be preferred. Writing a quick C# program that can take care of translation will barely take a full day.
I'm garnering from experience working as a developer for proprietary projects and K.I.S.S. approach has always worked the best. In this case the 'prototype' translation system is extremely simple - it only took me a few hours to throw that parser together. Yes it's that simple.
We should also not turn our back at the speed and performance benefits we'll get from this. All of the game strings would be stored in a contiguous block of memory. There is no fear of fragmentation or allocation overhead and the parsing speed is pretty amazing. Why waste time on complex third party libraries that might or might not do the trick we need, if we could get away with 150 lines of code that does it very efficiently?
but I'd be wary of spending time to solve problems other people have already solved over the past decades. It seems tools are out there to work with .po files, sourcing them from files in multiple languages. Writing a tool to parse our own custom translation format is yucky enough, do we want to be doing the same for entity and GUI XML, let alone arbitrary JS scripts and JSON data files?
You'd be amazed what people can do with Notepad++ alone. I had a friend from China who threw together a 100k ancillary/trait script for a mod; all done by hand. If we keep it simple and easy to edit, we'll definitely have them translated in no time.
Thanks for replying to this discussion, I really do agree all of this definitely needs to be thoroughly discussed, so the best possible solution is used.
I'm just advocating two things: 1) Translation file simplicity 2) Huge memory performance gain from using a dictionary object. -
Hi again. Localization became a topic again today and after some extensive feedback from Michael and his vision of things I decided to write a quick prototype of the system.
1) Language files
The system should be simple and allow easy modification of game strings. Localization strings should be placed into simple .txt files and the first part of the file name marks the language used, while the rest of the file name is ignored:
-) Format: {lang}xxxxx.txt
-) Example: english_units.txt
All files associated with a language will be collated into a single language dictionary.
2) File format
Since the files are simple text files, the format should also be simple, easy to edit and foremost it should be readable.
Each translation entry (id string from now on) is described first by its id string on a single line, followed by its attribute values, each on a single line. Each attribute is followed by a translation string, separated with white-space. An id string entry is terminated by an empty line. For the sake of parsing correctness, any empty lines should be ignored. Lines can be commented using a semicolon ;.
-) Format:;;; comment
id string
{attribute} {translation string}
{attribute} {translation string}-) Example:
athen_hero_pericles
generic Pericles
specific Periklēs
tooltip Hero Aura: Buildings construct much faster within his vision. Temples are much cheaper during his lifetime.
Melee 2x vs. all cavalry.
history Pericles was the foremost Athenian politician of the 5th Century.3) Current translation text
Now of course, the first concern of Michael was how to get all the current translations from XML to new files. It took a few minutes of scribbling to put together a tiny conversion tool. It simply shuffles through a set of sub-directories and collates xml files of a directory into a file.using System.Xml;using System.IO;namespace WFGLocalizationConverter{class Program{static string GetValue(XmlNode node, string key){if (node == null || (node = node[key]) == null)return null;return node.InnerText;}static void CreateTranslationFile(string path){string[] files = Directory.GetFiles(path, "*.xml", SearchOption.TopDirectoryOnly);if (files.Length == 0)return; // nothing to do hereStreamWriter outfile = new StreamWriter(string.Format("english_{0}.txt", Path.GetFileName(path)));outfile.WriteLine(";; Generated by WFGLocalizationConverter\n");foreach (string file in files){XmlDocument doc = new XmlDocument();doc.Load(file);XmlNode identity = doc["Entity"]["Identity"];if (identity == null)continue; // not all entities have <Identity> tagsstring generic = GetValue(identity, "GenericName");string specific = GetValue(identity, "SpecificName");string tooltip = GetValue(identity, "Tooltip");string history = GetValue(identity, "History");if (generic == null && specific == null && tooltip == null && history == null)continue; // no useful data for us// write it downoutfile.WriteLine(Path.GetFileNameWithoutExtension(file));if (generic != null) outfile.WriteLine("generic {0}", generic);if (specific != null) outfile.WriteLine("specific {0}", specific);if (tooltip != null) outfile.WriteLine("tooltip {0}", tooltip);if (history != null) outfile.WriteLine("history {0}", history);outfile.WriteLine();}outfile.Close(); // clean-up & flush}static void Main(string[] args){foreach(string path in Directory.GetDirectories("data/"))CreateTranslationFile(path);}}}
Running this tiny piece on "simulation emplates\", I get a full list of collated translation files:english_campaigns.txtenglish_gaia.txtenglish_other.txtenglish_rubble.txtenglish_special.txtenglish_structures.txtenglish_units.txt
4) Loading translation files
Now that we've converted all of this into the language files, we need to read it back in C++. In order to minimize memory usage, we load the entire file into a buffer, treat it as a string and tokenize it. The tokenized strings are then put into a hash map (std::unordered_map<size_t, TEntry>). Even though a sorted vector indexed with binary search would be more memory efficient, we resort to the hashmap for simplicity.
The code itself is written as a small C/C++ module (yeah, sorry - it's 175 lines):#include <stdio.h> // FILE* suits us a bit better in this case#include <unordered_map> // lazy today// good old k33 hashinline size_t hash_k33(const char* str){size_t hash = 5381;while(int c = *str++)hash = ((hash << 5) + hash) + c; // hash * 33 + creturn hash;}// tests if the range is ALL-whitespaceinline bool is_whitespace(const char* begin, const char* end){while(begin < end) {if(*begin != ' ' && *begin != ' ') return false; // found a non-ws char++begin;}return true; // this is all whitespace}// advances to the next lineinline char* next_line(char* str){return (str = strchr(str, '\n')) ? ++str : nullptr;}// reads a valid line (skipping comments and empty lines)const char* read_line(char*& str){char* line = str;do{if(*line == ';' || *line == '\n' || *line == '\r')continue; // next linechar* end = strpbrk(line, "\r\n"); // seek to end of lineif(is_whitespace(line, end)) // is it all whitespace line?continue; // skip line// window CR+LF ? +2 chars : +1 charstr = *end == '\r' ? end + 2 : end + 1; // writeout ptr to next line*end = '\0'; // null term this line, turning it into a C-stringreturn line;} while(line = next_line(line));return nullptr; // no more lines}// gets an attribute lengthinline int attr_len(int attrid){static size_t attrlens[] = { 0, 7, 8, 7, 7 };return attrlens[attrid];}// gets the attribute id [1..4] of this line; 0 if not an attributeint attr_id(const char* line){static const char* attributes[] = { 0, "generic", "specific", "tooltip", "history" };for(int i = 1; i <= 4; i++) {size_t len = attr_len(i);if(memcmp(line, attributes[i], len) == 0) { // startsWith matchconst char* end = line + len;if(*end != ' ' && *end != ' ') return 0; // it's not a valid attribute!return i; // it's a valid attribute}}return 0; // it's not a valid attribute}// UTF8 Translation Entrystruct TEntry{const char* idstring; // id string of the translation entryconst char* generic; // 'generic' attribute stringconst char* specific; // 'specific' attribute stringconst char* tooltip; // 'tooltip' attribute stringconst char* history; // 'history' attribute stringvoid set(int attrid, const char* line){line += attr_len(attrid) + 1; // skip keyword +1 charwhile(*line == ' ' || *line == ' ') ++line; // skip any additional whitespace*((const char**)this + attrid) = line; // hack}};// UTF8 dictionarystruct Dictionary{char* mBuffer; // buffersize_t mSize; // buffer sizestd::unordered_map<size_t, TEntry> mEntries;Dictionary(FILE* f){// get the file sizefseek(f, 0, SEEK_END); size_t fsize = ftell(f); fseek(f, 0, SEEK_SET);char* str = mBuffer = new char[mSize = fsize];// read all the data in one gofread(mBuffer, fsize, 1, f);const char* line = read_line(str);if(line) do {TEntry entry = { 0 };if(attr_id(line) == 0) { // not an attribute; great!entry.idstring = line;int attrid;while((line = read_line(str)) && (attrid = attr_id(line)))entry.set(attrid, line);// emplace entry into the hash table:mEntries[hash_k33(entry.idstring)] = entry;}} while(line);}~Dictionary(){delete mBuffer, mBuffer = nullptr;mEntries.clear();}inline const TEntry* at(const char* idstring) const { return &mEntries.at(hash_k33(idstring)); }inline const TEntry* operator[](const char* idstring) const { return &mEntries.at(hash_k33(idstring)); }inline const TEntry* at(size_t idhash) const { return &mEntries.at(idhash); }inline const TEntry* operator[](size_t idhash) const { return &mEntries.at(idhash); }};struct Entity{const TEntry* descr;// ...Entity(const TEntry* descr) : descr(descr) {}void Print() // print the unit{printf("%s\n", descr->idstring);if(descr->generic) printf("generic %s\n", descr->generic);if(descr->specific)printf("specific %s\n", descr->specific);if(descr->tooltip) printf("tooltip %s\n", descr->tooltip);if(descr->history) printf("history %s\n", descr->history);printf("\n");}};int main(){if(FILE* f = fopen("english_gaia.txt", "rb")){Dictionary english(f);fclose(f);Entity(english["fauna_bear"]).Print();Entity(english["flora_bush_badlands"]).Print();system("pause");}return 0;}
-----------
I'll put the main focus on how the Dictionary is actually used. For any given entity, we will assign a Translation entry which contains all the required strings we need. These Translation entries can be retrieved from the dictionary by their id string or its hash. This is done only once when the Entity type is instantiated.
Here's a snippet of this in action:struct Entity{const TEntry* descr;// ...Entity(const TEntry* descr) : descr(descr) {}void Print() // print the unit{printf("%s\n", descr->idstring);if(descr->generic) printf("generic %s\n", descr->generic);if(descr->specific)printf("specific %s\n", descr->specific);if(descr->tooltip) printf("tooltip %s\n", descr->tooltip);if(descr->history) printf("history %s\n", descr->history);printf("\n");}};int main(){if(FILE* f = fopen("english_gaia.txt", "rb")){Dictionary english(f);Entity(english["fauna_bear"]).Print();Entity(english["flora_bush_badlands"]).Print();system("pause");}return 0;}And its output in the console:
fauna_bearspecific Bearflora_bush_badlandsspecific Hardy Bushhistory A bush commonly found in dry flatlands and rocky crags.
This is it for now. What you should do now is discuss! You can take a look at the converted translation files below.
Regards,
- RedFox -
With the quadtree you lose efficiency when height is added since you need to search a larger area. Significant uses in our game are for culling what will be rendered and detecting units under the cursor for mouseover and selection. These are both 3d operations, 2d spatial filtering for gameplay already exists in CCmpRangeManager and the slowness here is not due to the spatial data structure at the moment.
I think that is incorrect. 0 A.D. uses a fixed-size subdivision implementation, which becomes very slow when a lot of units are in a small area. If a lot of these units are in a single area, they still generate a lot of range comparison complexity.
A proper quadtree implementation would allow dynamic and more precise subdivision of those areas, thus decreasing the amount of checks required even if a large number of entities are in a relatively small space.
Using an octree would provide no speed bonus in this area, since this is not an FPS where units can exist in different rooms and different heights. Adding an extra dimension would just slow down the algorithm, since each octree node will require +4 pointers and will generate +4 subnodes - if compared to a quadtree.
-
I see that there's not a consensus about
whether an octree is The Way, but if the dev manager likes it I'm willing
to go forward. I have some questions about what I'd be delivering.
First thing I'd like to point out is that 0 A.D. does not need an Octree (a 3-dimensional space partitioning structure). It needs a Quadtree (a 2-dimensional space partitioning structure). The position values in the Quadtree would still be stored as Vector3 values.
* I understand there are several different uses for an octree, including
graphical rendering, route finding, and so on. That suggests the best
interface is a pretty low-level one, e.g., I create an object of type
Octree and then just treat it as a sparse array in three dimensions. Is
that how you want to use it, or are there some operations (find a certain
value? copy? prune off everything under a certain node?) that are going to
be needed frequently enough to build it in?
A quadtree can be used for:
-) Efficient collision detection - you minimize the amount of collision checks by only checking objects in a single quadtree node.
-) Efficient pathfinding - you can minimize the number of grids checked by A* if you use a quadtree (
). Bigger cells have bigger movement cost values, so it works very well for long-range and short-range pathfinding.-) Range detection - you can easily get a small list of objects close to you just by checking the neighbouring cells.
-) Culling - its very easy to cull your world with a quadtree. You only need to compare the frustrum against the quadtree once. Right now 0 A.D. compares the viewing frustrum against all objects in the world.
* What data types are likely to be stored in the nodes?
-) A Quadtree cell should contain a singly linked-list structure that contains pointers to a generic "GameObject". This greatly speeds up add/remove/create on the cells.
The "GameObject" itself should contain Position.xyz, Radius, BoundingBox - everything needed for interactions between objects.
* I've found an open source templated octree class. Maybe this project is
already done, or maybe this implementation I've found is too slow. Can you
suggest what operation(s) need to be especially quick for our purposes?
A Quadtree is actually a very simple structure and in the best interest of speed, it should use a custom variant, with a Cell allocation memory pool and a Listnode allocation memory pool. Otherwise the amount of new/delete would cripple the implementation.
-
I'm also working on a pathfinder test. Hopefully I can contribute something based on it in the future.
-
1
-
-
Today's progress report on the custom layout engine:
-) Improved font-face loading:
Before I had to re-load a TrueType font file every time I needed a specific style and size font. Now it's optimized to work as it should - by using a single TrueType face and processing it through specified sizes.Of course, it required quite a lot of structural change again, but in the end, the'API'is a lot easier to use:
FontFace* face = new FontFace("fonts/veronascript.ttf");
Font* font = face->CreateFont(48, FONT_STROKE, 3.0f, 96); // fontHeight, style, outlineParam, dpi
Text* text = font->CreateText(L"Hello text!");
// ... render text-) DPI awareness:
With a multitude of different DPI settings out there, it was logical to make the font system DPI-aware. In this case, if the user has changed the default system DPI value, the fonts will be rendered accordingly. Increasing the DPI values will make the text look bigger(and thus more readable).I should emphasize again, that the DPI setting itself is a system-wide property and isto make the system text bigger. The default DPI value in windows is 96.Here's a sample with DPI 108:

-) What's still left to do:
- Implement embolden, slanting, underline, strikethrough.
- Improve the naive shelf-packing algorithm to achieve better texture space usage. (performance)
- Buffer all static text into a single Vertex Buffer Object, render by offset into buffer. (performance)
- Implement this beast into 0 A.D.
-
1
- Implement embolden, slanting, underline, strikethrough.
-
Nice post, but i have some concerns: Your unicode support is very limited when it comes to complex scripts [1][2]. I don't think texture-mapping of glyphs will work here. There are just too many combinations.
You have a fair point in Complex Text Layout limitations. Right now only common glyph based text could be displayed and that's bad for most eastern fonts. However with the current layout engine, I could easily create render-to-texture text instead of glyph sequences (I'm already doing it when creating the font-atlas texture).
Taking a look at the Pango documentation, it seems like a very complex library and will definitely be a pain to use.
However, we can use Harfbuzz separately to convert UTF-8 text into meaningful Unicode values and then generate text during runtime. We can easily toggle between font-atlas rendering for latin, greek, cyrillic and use render-to-texture text for arabic, indian, chinese...
There's even a cool example for this here: https://github.com/lxnt/ex-sdl-freetype-harfbuzz/
Right now I'd rather keep Complex Text Layout at the end of the priority list (it's just very fancy text rendering), but if it's deemed to be a 'must-be' feature by Michael, we could integrate Harfbuzz.
-
Nice post!
But will this require OpenGL 3.1 support? 0 A.D. currently only needs 2.1 and also still works with OpenGL 1.x (though it will probably be dropped).
This is a good question actually. If I change the shaders to target #version 120, it will work perfectly fine for OpenGL 2.1 and OpenGL ES 2.1. There's actually no reason it can't target those versions. The only reason I stated OpenGL 3.1 is because it completely relies on modern OpenGL, not on the old deprecated immediate mode.
It can't target older OpenGL versions though, since I'm using NPOT (non power-of-two) textures.
Regarding OpenGL versions in general, I think 0AD should target GLES 3.0+ and OpenGL 3.0+, since older hardware won't be able to run the game anyways.
-
A few weeks ago Michael (Mythos_Ruler) mentioned his problem with current 0 A.D. bitmap fonts - they seem to fall quite short from rest of the art content, mainly because:
- Texture fonts aren't scalable (you need to generate fixed sizes).
- No dynamic font stroke, outlines or drop-shadow effects (unless baked into the texture).
- No wide Unicode support (cyrillic, greek, extended latin, arabic, etc.).
- Small text is quite hard to read (no font hinting).
I've been working on this problem for the past two weeks and decided to give you some insight to the work.
1. Old bitmap fonts
The old bitmap-font system in 0 A.D. is very simple, yet limited. A bitmap font is usually generated with an external tool and contains glyph information (*.fnt) and the bitmap (*.png). To illustrate, here is the current 0 A.D. 'Serif 12px' bitmap:

You can immediately notice that most characters looks somewhat pixelated and dirty, making some characters pretty hard to read. This is mostly due to imperfect anti-aliasing for small scale fonts and no font hinting.
Adding new fonts is especially difficult, since you need to generate font bitmaps for any variation you want. Say you wish to have Arial text in sizes 10, 12 and 14; you also might want regular, italic, bold, bolditalic styles. You also might want to have a regular, stroked and drop-shadow variant.
If you had to generate all these bitmap fonts, you'd quickly have [sizevariants] * [stylevariants] * [fxvariants] font variants. In this case it might be 3 * 4 * 3 = 36 variants. So now adding a new font into the game with all the features you want turns out to be a real hassle since you need to generate so many variants that its crazy. Running tests to find your 'favorite' font and style combination quickly becomes pretty much impossible. Once you've generated your Arial variants, you'll just be glad its over.
Furthermore, if 0 A.D. ever wishes to become a fully localized / multi-lingual game, at least partial unicode support is required to draw cyrillic, greek, extended latin, arabic, etc. glyphs. Can you imagine generating bitmap fonts for such a broad variety of languages? Add 6 different codepage support and you'll be looking at 36*6 = 216 bitmap fonts.
Currently 0 A.D. bitmap fonts range from plain ASCII and Latin1 up to Latin Extended-A, which basically just covers most western characters. If you wanted to add support for Greek characters, you'd need to either regenerate all fonts to add the glyphs you need, or you'll have to create a separate bitmap for just Greek characters. That would be like reinventing codepages.
2. TrueType and FreeType
A few decades ago this problem was addressed by designing a vector-based font format, which we now know as TrueType. I'll spare you the details, but the gist of it is to use vector outlines to describe all the style variants for every glyph in the font.
There are only two issues here: 1) Getting a font that supports all the glyphs you need. 2) Reading these complex font files and turn them into an image.
First is easily solved, the web is full of TrueType fonts: http://www.fontsquirrel.com/
Second is a lot harder, but luckily enough, we have the FreeType library: http://www.freetype.org/
Still though, Freetype isn't designed to be a full-fledged text displaying engine. All it does for us is a specific glyph image and some sub-pixel data to position it correctly.

The rest is all up to us. We have to actually do the hard thing and get all this data through OpenGL 3.1 and onto the screen.
Note: Due to some specific design decision, using an existing library like freetype-gl was out of the question and as we can see later, the end result is better optimized to our needs.
3. Runtime texture atlas
This is exactly like bitmap fonts, with one major difference - we generate the texture atlas during runtime to suit our needs. If we need an emboldened font, we'll only generate that and be done with it.
The first step is to generate the basic ASCII subset, which is [0..127] inclusive, which is actually easy enough to do. We use a very basic shelf-styled packing method to create an 8-bit RED channel bitmap with just the size we need. The only requirement set by OpenGL is to align image width to 4-byte boundary.
We use a neat font called 'Anonymous Pro' - a monospace font that looks perfect for lots of text:
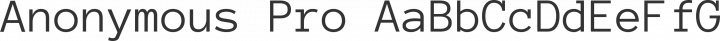
Using freetype library, some programming hocus-pocus and the simplest shelf-packing algorithm, we get a neat 1-channel bitmap for our 'Anonymous Pro 12px':

Can you notice the extra clarity compared to the 'Serif 12px' texture font? If you zoom in really close, you'll actually notice that the characters are neatly anti-aliased and also somewhat distorted. This is because 'auto-hinting' was enabled in order to make the small font look sharp and clear - making it a lot easier to read at smaller sizes.
4. Glyphs
We also need to store information about every character - or glyph in the atlas, otherwise we wouldn't know how to display it:
struct Glyph
{
ushort code; // unicode value
ushort index; // freetype glyph index
byte width; // width of the glyph in pixels
byte height; // height of the glyph in pixels
byte advance; // number of pixels to advance on x axis
char bearingX; // x offset of top-left corner from x axis
char bearingY; // y offset of top-left corner from y axis
byte textureX; // x pixel coord of the bitmap's bottom-left corner
ushort textureY;// y pixel coord of the bitmap's bottom-left corner
};Since we could have a lot of these glyphs (several thousand in fact), it's in our (and L2 cache) best interest to keep them small. In this case, each glyph has been optimized to be exactly 12 bytes in size and keep all the needed information to render and place a glyph.
To make glyph lookup faster, they are placed in a vector and sorted by the unicode character value. Each lookup is done with binary-search, which keeps it consistent and very fast. We should also remember that OpenGL textures are bottom-up, so pixel 0 would be the bottom-most and pixel N the topmost.
5. OpenGL 3.1 and a custom Text Shader
Now that we have everything we need, we actually have to display the glyphs on the screen. In OpenGL, everything is displayed by using Triangles and the same applies to this case. With some additional testing, I found that using a single Vertex Buffer Object with 6 vertices per glyph is the fastest and most memory efficient version. This is mostly due to the small size of the Vertex2D structure:
struct Vertex2D
{
float x, y; // position.xy
float u, v; // coord.uv
};The generated glyph Quad itself looks something like this:

The simplest fragment shader to display our text in any color:
#version 140 // OpenGL 3.1
varying vec2 vCoord; // vertex texture coordinates
uniform sampler2D diffuseTex; // alpha mapped texture
uniform vec4 diffuseColor; // actual color for this text
void main(void)
{
// multiply alpha with the font texture value
gl_FragColor = vec4(diffuseColor.rgb, texture2D(diffuseTex, vCoord).r * diffuseColor.a);
}Which basically gives our Quad a color of diffuseColor.rgb and makes it transparent by using the font-atlas texture.
Once displayed on the screen, both filled and wireframe views of the same text:

Great! We now have a neat mono-space font perfect for displaying readable text.
6. Freetype
If we dig through some Freetype documentation, we will notice that the library also supports:
- Glyph stroke - Will give a neat outline to our fonts
- Glyph outline - You can just render an outline of a character.
- Glyph emboldening - You won't need a 'bold' font.
- Glyph slanting - You can generate italic text on the go.
- Auto-hinting - Makes small text more readable (http://en.wikipedia....ki/Font_hinting)
Using some simple code-sorcery, we can also add text shadows, which makes small text several times more readable on pretty much any background.
Stroke effect (48px white font + 3px black stroke):

Outline effect (48px white font + 1.5px outline):

Shadow effect (48px white font + 2px black shadow):

7. Magic of Stroke and Shadows
The stroke and shadow effect can have their own Outline color, in order to achieve this, we actually need to use another channel - Green. So for stroked and shadowed text a 2-channel Red-Green texture is generated instead of a 1-channel Red.
The best way is just to show the generated Red-Green texture:


You can see how powerful this sort glyph imaging is, since you can combine any kind of Diffuse and Outline colors to create your text effects. Best of all, fonts that don't use this effect still use a single 1-channel Red bitmap.
Even though the glyphs look really sharp and anti-aliased, they can be made blurry by just lowering the Outline alpha.
The shader used to combine this effect and work consistently for both 1-channel and 2-channel bitmaps, looks like this:
#version 140 // OpenGL 3.1
varying vec2 vCoord; // vertex texture coordinates
uniform sampler2D diffuseTex; // alpha mapped texture
uniform vec4 diffuseColor; // actual color for this text
uniform vec4 outlineColor; // outline (or shadow) color for the text
void main(void)
{
vec2 tex = texture2D(diffuseTex, vCoord).rg;
// color consists of the (diffuse color * main alpha) + (background color * outline alpha)
vec3 color = (diffuseColor.rgb * tex.r) + (outlineColor.rgb * tex.g);
// make the main alpha more pronounced, makes small text sharper
tex.r = clamp(tex.r * 2.0, 0.0, 1.0);
// alpha is the sum of main alpha and outline alpha
// main alpha is main font color alpha
// outline alpha is the stroke or shadow alpha
float mainAlpha = tex.r * diffuseColor.a;
float outlineAlpha = tex.g * outlineColor.a * diffuseColor.a;
gl_FragColor = vec4(color, mainAlpha + outlineAlpha);
}It looks a bit more complex, but the idea is simple: combine R and Diffuse, combine G and Outline, add them together.
8. Going Unicode
Now it's nice that we could achieve all this with plain ASCII, but we still haven't touched Unicode. The main reason it's so hard to support Unicode, is because there are thousands of combinations of different glyphs. It's impossible to generate all of them into a single texture - you'll easily overflow the 16384px limitation of OpenGL textures. Worst of all, even if you generate all of them, you'll probably only use 5% of them.
This is also something that freetype-gl is bad at. It's only useful for generatic a limited subset of glyphs into a single texture. If you want to support unicode, you'll go crazy with such a system.
To be honest, I also had to scratch my head quite a bit on how to solve this. If I were to use regular texture coordinates [0.0 - 1.0] on the glyph quads, they would immediatelly break if I resized the font-atlas texture. So using any conventional means pretty much flies out of the window.
The solution is pretty obvious, I have to use pixel values for the texture coordinates and generate the actual texture coordinates in the Vertex Shader. Now if I add glyphs to the end of the texture, thus resizing it, I won't break any glyph coordinates. The Vertex Shader:
#version 140 // OpenGL 3.1
attribute vec4 vertex; // vertex position[xy] and texture coord[zw]
uniform mat4 transform; // transformation matrix; also contains the depth information
uniform sampler2D diffuseTex; // alpha mapped texture
varying vec2 vCoord; // out vertex texture coord for frag
void main(void)
{
// we only need xy here, since the projection is trusted to be
// orthographic. Any depth information is encoded in the transformation
// matrix itself. This helps to minimize the bandwidth.
gl_Position = transform * vec4(vertex.xy, 0.0, 1.0);
// since texture coordinates are in pixel values, we'll need to
// generate usable UV's on-the-go
// send the texture coordinates to the fragment shader:
vCoord = vertex.zw / textureSize(diffuseTex, 0);
}The code for generating text looks like this:
Font* font = new Font();
font->LoadFile("fonts/veronascript.ttf", 48, FONT_STROKE, 3.0f);
VertexBuffer* text = new VertexBuffer();
font->GenerateStaticText(text, L"VeronaScript");If I were to include any unicode characters like õäöü, the font atlas would automatically generate the glyphs on-demand and add them into the atlas.
font->GenerateStaticText(text, L"Unicode õäöü");Here's a simple before-after comparison:

With this neat feature, we can support the entire unicode range, as long as the entire range isn't in actual use. If the texture size reaches its limit of 16384px, no more glyphs are generated and all subsequent glyphs will be displayed using the 'invalid glyph'.
9. Addendum
In the first paragraph, four problems of current 0 A.D. texture fonts were raised. Now we have provided solutions to all of them:
- Freetype allows dynamic font scaling.
- Freetype provides dynamic font effects (stroke, outline, embolden, italic).
- Unicode support depends on the .ttf font. The provided method ensures reasonable unicode support.
- Freetype provides auto-hinting, which drastically improves small text readability.
The new Freetype OpenGL font system solves all these issues by introducing truly scalable vector font support, with any required font effects and full Unicode support. From my own testing I've ascertained that using shadow style drastically improves readability of text.
Regarding performance:
Even with large volumes of text, there was no noticeable performance hit. Volumes of text that are all in a single Vertex Buffer Object especially benefit from very fast render times. The more text you can send to the GPU in a single VBO, the faster the rendering should be in theory.
What's still left to do:
- Implement embolden, slanting, underline, strikethrough.
- Improve the naive shelf-packing algorithm to achieve better texture space usage. (performance)
- Improve font-face loading to share between font-atlases. (performance)
- Buffer all static text into a single Vertex Buffer Object, render by offset into buffer. (performance)
- Implement this beast into 0 A.D.
I hope you liked this little introspect into the world of real-time text rendering.


Regards,
- RedFox
About Jorma Rebane aka 'RedFox': Jorma is a 22-year old Real-Time Systems programmer, studies Computer Engineering at Universitas Tartuensis and enjoys anything tech related. His weapon of choice is C++.
-
6
- Texture fonts aren't scalable (you need to generate fixed sizes).
-
Wouldn't it be better to implement an octree, to be more flexible if 3d ever plays a significant role?
Flexible? You mean when 0AD transforms into Homeworld and then the Z axis (or Y axis in opengl) finally plays a role? Yeah... not likely.
I wouldn't rule it out. If it's not too expensive (I'm speaking CPU-wise here), we could use it to have better frustrum cullings (such as removing bushes that can't be seen but not big trees or something). It would probably need to be slightly clever, though. And it'd indeed be nice to have. But if it leads to a somewhat significant slowdown, then scrap it.
For an octree, each node will take almost twice as much memory and there will be twice the number of nodes. So an octree will actually take ~4x amount of memory. It will also be around 4x slower since all quadtree traversals will include an exponentially larger amount of nodes. At any rate, I think it's kind of pointless to have an octree. 0AD is a strategy game with units on the ground. If that's not an obvious place for a quadtree, I don't know what is. Any entity will still retain it's X, Y, Z position, so range finding will work correctly.
Consider the case where an unit is on a wall and another unit is directly under it, for example 5m below. Even though in the quadtree they are in the same grid, their effective squared-distance will yield 25, which means they are nowhere near each other.
The goal of using a quadtree is to minimize unnecessary collision and range tests, not completely rule them out.
-
Has someone taken up the octree project? This seems like a nice, self-contained project for a new volunteer, and I'd like to pick it up.
...
I haven't done any game development, which is actually one of the reasons I'd like to work on a more abstract module like this one. I get that it can be used to represent a 3d space, but I'm ignorant of how we would go from the data structure to, say, a rendered scene.
It's an excellent place to start. Though 0AD doesn't require an octree - but a quadtree. Since it's a top-down strategy game not an FPS, only movement in the 2 dimensional plane really matters. What needs to be built into the quadtree implementation is range comparison and collision detection. They are different in the sense that collision detection only takes place inside a single quad while range finding expands outwards into quads that are in range.
-
I appreciate the detailed response, you've evidently spent a lot of time trying to get around temporary object creation. I need to look at the disassembly of the calls to understand what is going on behind the scenes a little better, I'm actually very surprised that the stack copying isn't optimised out but then C++ is a new beast for me. Anyway thanks again for the detailed response.
I guess it's because I come from a background of C, where being in control of every aspect of the program is really important. Inheriting from that, having code that generates hidden behavior behind the scenes can make development a real bane.
The question now is what is the way forward with the C++ code base.
Aside from a definite need to move the codebase to C++11, I think we should agree on a list of performance topics to add to http://trac.wildfiregames.com/wiki/CodeAndMemoryPerformance.
First part should be filled with general C++ knowledge that's not obvious for everyone. Perhaps excerpts from 'More Effective C++' by Scott Meyers? His book does a really good job at covering the basics. It might look a bit 'well, duh' for seasoned C++ developers, but it will definitely reveal new details.
Second part should cover algorithmic design, or 'optimize as you go' - simple design alterations to code to make it run faster, yet perform the same algorithm.
Lastly, it should finish with memory specific optimizations, data alignment and how to use new/delete more efficiently. For example: how to use alloca - a C standard library function from <malloc.h> that creates a dynamic memory block on the stack.
The current code and memory performance wikipage is very very brief. I think every point deserves a tiny code example. Why? Not everyone immediately picks up on ambiguous or made-up abbreviations.
{kind=link}
Floating props
in Game Development & Technical Discussion
Posted
Sounds like a good idea for building props. I'd even go so far to suggest we apply the terrain Z to every mesh group in the model that has same Z value as the foundation. This would let us keep the current art unmodified and it would require less from the 3d artists. Mesh groups that have higher Z will be ignored (clay pots on pillars, etc.).
This means that the model has to be broken down into sub-objects during loading time. Mesh groups with high Z value stick to the original object, while other mesh groups get extracted.
I don't even know how the model importing system works in 0 A.D., though, so perhaps someone else could comment on that.