phosit
-
Posts
288 -
Joined
-
Days Won
6
Everything posted by phosit
-
There is work done towards a alternating placement. But that isn't commited yet Can you upload the replay?
-
The OPEX cost would make the popcap a less hard limit. Which is good IMO.
-
I like how the cities integrate in to the terrain. In 0 A.D. the maps who have cities protected by cliffs are mainly acropolises. Which look unnaturally exposed.
-
It's likely the same error as this one: https://wildfiregames.com/forum/topic/95151-i-dont-know-what-to-do-can-someone-help-me-and-explain
-
Thank you for all your time. You always had the overview but still commented on many small things. I apreciated that.
-
Random map way too random when created in the Editor...
phosit replied to krt0143's topic in Game Modification
Why do you always write statements that contradict itself... Did you generate a "Survival of the Fittest" before? Then it could be due to this bug. I'm working on such a diff (Not the whole map will be flooded) -
"Elephantine" map - How do you get across the Nile?
phosit replied to krt0143's topic in General Discussion
I don't know what's the cause. Propably there is now less space for the Kushite units... Did you just smooth the shorelines or did you also add a tree? -
"Elephantine" map - How do you get across the Nile?
phosit replied to krt0143's topic in General Discussion
It's not commited yet. I expect it will be commited untill a27. -
"Elephantine" map - How do you get across the Nile?
phosit replied to krt0143's topic in General Discussion
To take advantage of the patch you have to get the development version and apply the diff or make a mod out of it. -
"Elephantine" map - How do you get across the Nile?
phosit replied to krt0143's topic in General Discussion
That's what D5136 tries to do. Doesn't it work for you? -
Question: Headless Replays
phosit replied to Dizaka's topic in Game Development & Technical Discussion
Do you mean "non-visual-replays", started with "./pyrogenesis --replay=<path_to_commands.txt>" ? The code is in "source/ps/Replay.cpp". -
IIRC @wraitii and @Langbart use macs. But i don't know if they use M1.
-
AI Behavior (surrendering, taunting, strategy, etc.)
phosit replied to wowgetoffyourcellphone's topic in Gameplay Discussion
Oh, and there is #2344 which also uses the word "persoality" but with a different notion. -
AI Behavior (surrendering, taunting, strategy, etc.)
phosit replied to wowgetoffyourcellphone's topic in Gameplay Discussion
I think for new players understanding AI Behavior {Random, Balanced, Defensive, Aggressive} is easyer then Personalities. I image myself always searching the personality who is most likely defensive. On the other hand it's less abstract to play against a personality instead of a set of attributes. It would be nice if we can play against (the personality of) "the enemy in a campain" outside the campain. I don't agree with the proposed attributes {Aggressive, Defensive, Balanced} because they are only values on the Aggressive-Defensive-Spectrum. I'm more for a single value: Aggressiveness of 0.17 is defensive. Aggressiveness of 0.5 is balanced. Aggressiveness of 0.83 is aggressive. Not realy related to your "Personalities" idea but i would like when AI's have another degree of freedom appart from "AI Behavior" (which should be called Aggressiveness IMO). A new degree of freedom like "Supportivity": An AI which is not supportive never sends their allies resources and does not help in wars of allies. An AI which is very supportive often sends their allies resources and sends many units to help in the wars of allies. (even if the eco of the AI is going to die) About the surrendering there is #2195 -
Hello Mr.lie, Thank you for the report. Can you try to make and load a new savegame with the proposed fix at https://code.wildfiregames.com/rP27722 ?
-
Random (not Skirmish or Scenario) don't have a default value. Values from 1 to 8 (inclusive) can be selected. For now the maximum number is 8 so you can't increase it beyond that.
-
Implement Multithreading to this game
phosit replied to inzhu's topic in Game Development & Technical Discussion
Some tasks are done off of the main thread. (There is an overview.) The most computation (simulation and rendering) is done on the same thread. Only one thread can work on a spidermonkey-context (where the simulation is computed). Copying data from one context to another is performance intensive (compared to not doing it). So splitting the tasks on a per unit level results in much overhead. I think doing the rendering on a different thread has more chances to yeald an improvement. I hope i didn't destroy your motivation. We can always use help. Fell free to join The irc chanel or DM me. -
It's relatet to this ticket: https://trac.wildfiregames.com/ticket/3517 The difference I see is that in the ticket there is no place to ungarison the unit, where in your picture there is enough.
-
I like the idea for the "bonus for fields". Plants need water to grow. I don't see the direct relation to the "more population in CC". People might be less busy carrying water so they can participate in economy or military.
-
@seeh I know you are interested in that.
-
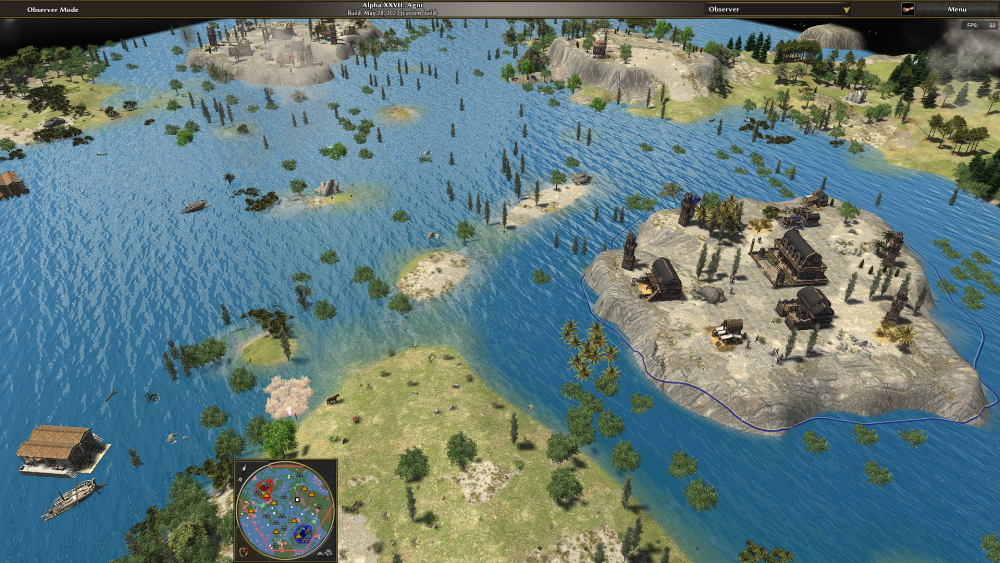
Monsoon is a seasonal weather phenomenon. There is heavy rain and the water level of the rivers and lakes does rise. But i guess you know that already. This mod does bring that to 0 A.D. This is cantabrian highlands during the monsoon. Note: In the real world cantabria isn't at the latitude where the monsoon occurs Monsoon has negative and positive effects. Units drown, and building get washed away (well they get destroyed), ships... No ships swimm but they get destroyed when they go aground. Some resources vegetate during the monsoon. Fields survive the monsoon. The Mauryas have a bonus because they where faced with the monsoon. Actualy it's just because they have moveable dropsides(the elephants) which can also be garrisoned in ships. The docks float. I don't know if I should declare that a feature or a bug. Apart from that I don't know what to write. And i'm running out of jokes. You can find the code here. Epsilono.pyromod Edit: I forgot somethng: PetraAI doesn't play well with Monsoon. Hopefully we can organize a match in this thread. Monsoon is supported on thous maps: Cantabrian Highlands Acropolis Bay Death Canyon Deccan Plateau Greek Acropolis (only two player map) Greek Acropolis Night Miletus Peninsula Tuscan Acropolis


- 1 reply
-
- 2
-

-
It looks like the animals are climbing where they shouldn't be.
phosit replied to Delfador's topic in Bug reports
In Acropolis Bay(2) which is kind of the default map some Red Deer start in impassable terrain. It's a skirimish map so somebody had to place them explicitly there.
-
Quick experiment with shorter turn lengths
phosit replied to wraitii's topic in Game Development & Technical Discussion
Do you have a clue why there are the two spikes in `OnUpdate`?
-
Quick experiment with shorter turn lengths
phosit replied to wraitii's topic in Game Development & Technical Discussion
Shorter turns will yield a smoother game play and less latency but add more "overhead": even if the range-queries are fixed there will be some constant factors. Regarding smoothnes: IMO the biggest problem is that when the AI does recalculate their diplomacy, frames sometime take multiple seconds. If you reduce turn length this will be much more noticable. The AI in general does lead to long turns. Anolog to what you propose the AI could be run more frequent. I don't know if there are constant factors in the AI code. Regarding latency: I don't think of 0ad as a fast paced game so I don't value latency that high. If we still care there are better solutions: make the "turn count untill the input take effect" dynamic in MP games. I'm more in favor of split rendering from simulation. That would make the game a lot smoother by increasing latency (since the simulation or the draw commands have to be buffered somewhere). -
That's an two player map how did you manage to place eight players on it?