

Yves
-
Posts
1.135 -
Joined
-
Last visited
-
Days Won
25
Posts posted by Yves
-
-
I don't expect it to be too be extremely difficult and dangerous, but it's definitely not done in a few hours.
The basics of the rooting API are relatively easy, but there are some difficulties with special cases.
Templates and macros are a problem because you need different types depending on where they are used (JS::Rooted<T> for declaring new variables on the stack, JS::Handle<T> or JS::MutableHandle<T> for function arguments). Templates will just be instantiated as a template function with the type you pass in (JS::Rooted<T>), but arguments should be passed as handle types. Even if you define only a JS::Handle<T> spezialization, it will still complain that there's no spezialization for JS::Rooted<T> instead of using the implicit conversion to a handle which is available. JS::MutableHandle<T> isn't a problem here because it uses the & operator, but JS::Handle<T> needs an explicit cast.
It's more difficult in combination with macros because they implement generic code for types but we need special code (like these casts or the & operator) for these special types. This is a problem in the ScriptInterface::FromJSVal implementation. It either requires a lot of code duplication or a smarter solution which I haven't found yet.
Another problem are places where JSObject pointers are used as identifiers and are mapped to some other values. Ticket #2428 is such an example.
isn't this philosophy of 'developer is responsible for telling which is to be garbage collected' better solved by the philosophy 'developer is responsible of trashing invalid pointers directly' ?
This just follows the same approach the Javascript garbage collector does (marking what's still used).
Making the API user responsible for freeing unused variables wouldn't be much better because instead of crashing you could end up with memory leaks (values not being used anymore which haven't been marked as unused properly). It could also lead to problems or at least inconsistencies when passing values from JS to C++. They are JS values and therefore would be automatically collected and then you also have them on the C++ side where they would not be automatically collected (but both are actually the same value). You can also have a call stack going from C++ to JS and back to C++. In this case you would have to check the whole stack for values still in use from C++ (which is what the stack scanning did).
-
KeepJitCode was the one where Jit code is not garbage collected, right? Do the Mozilla Devs plan to make this safe in ESR31? I honestly don't know how this could work with a moving GC?
H4writer pointed me to bug 984537 which is planned to get into ESR31.
I can test this patch and see if it really solves the problem for us, but according to him it should.
-
 1
1
-
-
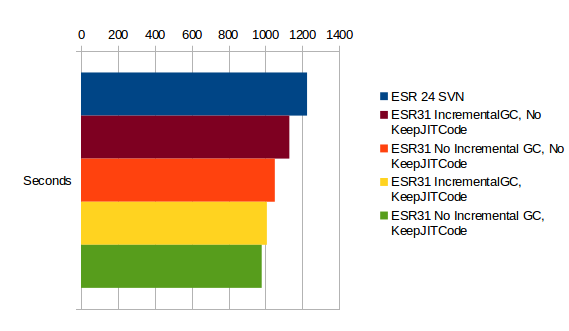
So the conclusion is: All ESR31 versions are slower.
So why should we go for ESR31 anyway?
No they are faster!
The graph shows how many seconds the 15000 turn replay took, so shorter bars are better!
Edit: I have no idea why Libre Office Calc orders the items in the legend bottom-up and the graphs top-down but the colors are what matters.
Edit2: I've fixed the order in the graph
-
This thread is for discussions and updates about the SpiderMonkey upgrade to ESR31
I've decided to create a new thread because getting the upgrade to ESR24 into SVN was an important milestone and the previous thread was already quite long.
Ticket: 2462
Check it out from my github branch (read the readme!).
Short summary what happened so far
The upgrade from the old SpiderMonkey version v1.8.5 (released in March 2011) was quite a big task due to the API changes.
The conceptual changes (like having a 1to1 releation between global objects and compartments) were the biggest problem. Another problem were inconsistencies and duplication in our own code. The smaller problem were simple API changes. These issues are sorted out now and we can continue with the upgrade to ESR31.
Performance
We expected a lot from the upgrade to ESR24 because most of the significant SpiderMonkey changes from v1.8.5 to v24 were solely to improve performance.
There's a new baseline compiler, a new JIT compiler with enhanced optimization capabilities called Ion Monkey, improved type inference and a lot more. There was a whole team of programmers working on performance improvements over years. The commonly used benchmarks show a big improvement but unfortunately we figured out that this does not improve performance for us and the performance got a little worse with the upgrade.
It's not a big secret that these benchmarks get "special care" from the developers of Javascript engines such as SpiderMonkey or V8. Browser market shares are the main factor deciding how much money these companies get from e.g. search providers for adding their search as default entry in the browser. Benchmark performance improvements seem to be important for marketing, which is where the term "benchmarketing" comes from.
The benachmarks were originally desigend to be a good representation of real world application performance but now one could say they are not related to real world performance anymore because of all the tuning and benchmark specific optimizations.
Still, I trust Mozilla that the fundamental engine changes will also improve performance for embedders like us at some point (and probably they already do). What they did first after integrating big changes like Ion Monkey or Baseline was making sure they don't decrease benchmark performance. Now that this goal is completed they can start fixing performance issues which don't show up in these benchmarks but are important for other applications. H4writer fixed some of these problems we reported during the upgrade to v24 and apparently they continued fixing others in the meantime.
ESR31 schedule
ESR31 is still in development. We have time until the end of the month to get changes in, so I'm starting early with the work on the upgrade (well, as early as I could).
That should also help detecting performance regressions and ease the integration of API changes.
The final version should be released in July and I'm aiming for Alpha 17.
Exact rooting, moving GC and GGC
While upgrading to v31 I'm also working on the transition to exact stack rooting and the support of a moving garbage collection (GC).
V31 will probably be the last version supporting conservative stack scanning (the opposite of exact rooting). This change should bring some performance improvements, in theory, but we'll see what happens in practice. This transition will allow us to use features such as generational garbage collection (GGC) and compacting garbage collection in the future. The progress is tracked in #2415.
Performance: current status
V31 really brings some improvements compared to V24. Unfortunately I can't compare it to v1.8.5 easily anymore.
I've used a non-visual replay with 4 aegis bots on the map Oasis 04 over around 15000 turns and measured how long the whole replay takes.
This shows the difference more clearly than the graphs I've used before.
I've found a bug with incremental GC causing problems with off-thread compilation of JIT code. I've reported the incremental GC problem on the JSAPI channel and they created bug 991820 for it.
I've also confirmed once more that disabling garbage collection of JIT code makes a difference. Unfortunately there are currently only functions meant for testing purpose which allow us to do this and I'll ask for a proper solution soon.
Here's the comparision with different variations concerning the problems mentioned above:
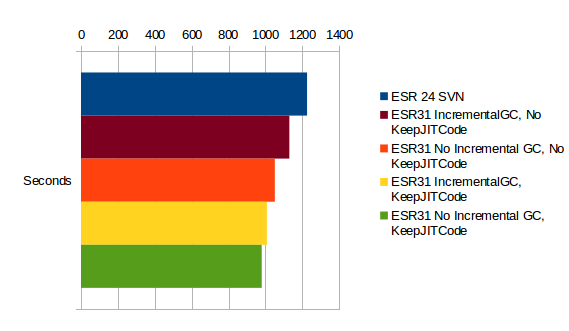
-
5
-
-
I'm aware that there are still warnings left.
SpiderMonkey 24 prints more warnings than v1.8.5. We could switch off the additional warnings, but leave them enabled instead and will have a look at them in the next weeks.
It doesn't have priority for me though and I probably won't fix them within the next few days.
-
@agentx
Have you really tested these cases?
It doesn't always warn you when a value is undefined.
I've tried something very similar.
I've added this line to multiple files of aegis:
m.Val = m.Val || "filename.js";
It didn't cause any warnings.
-
I've played a game on this map and I like it very much.
It looks good and works well for gameplay!
-
3
-
-
The SpiderMonkey upgrade is now committed to SVN and an autobuild is done.
You can easily test it now.

I've tried to understand the SciptInterface C++ code in 0AD, but I'm far away from understanding what's going on. Let aside the changes you've mentioned. Apparently it is now possible to connect a gdb? Not sure whether this provides JS variable inspection.
GDB can only be used for the C++ JSAPI code and not for Javascript code.
I think they added some pretty printers that now show more about the values inside the JS types.
Some code changes are needed to attach an external debugger, but I hope there's a way that allows us to use an existing debugger as client and only a little bit of JSAPI code.
-
2
-
-
@gameboy
The warnings you reported today aren't related to the new AI.
I've committed the SpiderMonkey upgrade yesterday and it enables some more warnings.
We plan to look at these and solve them properly.
EDIT: well one was... but it looks like mimo fixed it.
-
I've commited in svn a new ai bot (Petra) which was developped starting from Aegis, but heavily modifying it with the goal to be more robust according to external conditions.
I'm looking forward to testing it!
Could you elaborate a bit on how it reacts better to external conditions?
-
1
-
-
I think you need to install visual studio 2008 express to get that DLL.
I'm not quite sure about that though. If you build in release mode it won't need the debug DLL and it should work.
IIRC the redistributable will only provide the release version of the DLL (without the d suffix).
-
Wow some of these maps look gorgeous!
Too many Cypress trees can look a bit weird like in this example:
./pyrogenesis -autostart-random=6200 -autostart-size=384 -autostart-players=4 -autostart=realisticTerrainDemo
And there are some cases where there are so many trees that:
- The spatial subdivision problem occurs. But that's an engine problem and not a problem of the random map.
- It lags very bad.
Maybe you should still try to limit the density of forests with some sorts of trees a bit.
An example causing a lot of lag:
./pyrogenesis -autostart-random=600 -autostart-size=384 -autostart-players=4 -autostart=realisticTerrainDemo
Generally the maps are generated relatively quickly (less than 10 sec for this size), so I don't know if tuning even makes sense.
Why do you want faster map generation?
EDIT:
The winter maps with snow look the best IMO. Other biomes sometimes have a bit boring ground textures.
This map is my favourite so far (with some AI players, enjoy the battle!):
./pyrogenesis -autostart-random=7555 -autostart-size=256 -autostart-players=4 -autostart=realisticTerrainDemo -autostart-ai=1:aegis -autostart-ai=2:aegis -autostart-ai=3:aegis -autostart-ai=4:aegis -autostart-civ=1:gaul -autostart-civ=2:brit
-
1
-
For heightmap data I suggest you have a look at typed arrays.
They should be the best data structure for compact single-typed array data.
That should allow the JS engine to pack the data very closely and should make copying of the whole array efficient. It should just be a single copy of a memory block.
If you use a normal object and the JIT compiler has to figure out that it can pack the data as a compact array, that might not work. If it has to fall back to a generic object structure that's much less efficient. That's the theory at least...
EDIT: We have some code using typed arrays, but they probably aren't fully supported by SpiderMonkey v1.8.5.
If everything goes well I'll commit the upgrade to v24 in a few days though.
-
1
-
-
The SpiderMonkey upgrade is ready for review.
Check the comments on trac and get it from my github repository if you want to help testing and reviewing.
-
4
-
-
Thanks for the input and the support!
At the moment I'm looking into how it works technically and what our possibilities are.
There are a lot of potential designs but in the first step I don't worry about productive development processes or licensing topics.
I mean we could do something like Mozilla with their mozilla-inbound repository where stuff gets committed first before it goes into mozilla-central.
We could also checkout custom github repositories or branches and run our tests there. Maybe we could download and apply smaller patches.
All that not only needs to work technically, but there are security concerns (we are downloading and executing code) and processes need to be defined.
For a solution like the inbound-repository for example, there are a lot of unanswered questions at the moment. Are there manual steps involved? Will committing be queued when one patch is being tested? What happens if a change that comes earlier in the queue breaks the a later patch in the queue etc.
I plan to look into how different systems (Windows, Linux, Mac) can be connected and if data can be aggregated at the same place.
I'll focus on the technical aspect first.
-
2
-
-
Some probably know Jenkins already. It's an Open Source tool for automated building and testing.
The idea is to notice bugs as soon as possible after they are introduced. Let's compare this situation with and without Jenkins to show what I mean (not using Bob and Alice as names for once):
Situation: Yves breaks a test only in debug builds
Currently (without Jenkins): Yves has tested his change in the game and he has launched the tests in release mode. Everything works as expected and he commits.
Two weeks later there's a forum post about a strange problem with the tests. Leper and Sander both can't reproduce it in their first try. On their systems the tests work well. After a few questions in the forum they figure out it only happens in debug builds and after an hour of collaborative analysis they find and fix the problem.
Unfortunately some other commits were based on this change during the last two weeks and more changes need to be done.
Future (with Jenkins): Yves has tested his change in the game and he has launched the tests in release mode. Everything works as expected and he commit.
Jenkins does some automated building and testing with various configurations. One hour later, Yves gets a mail from Jenkins informing him that the tests don't work in debug mode. Yves has worked on the change just an hour ago and everything is still fresh in mind and he can solve the problem quickly because he already knows where to search for it.
That's an optimal case but there are a lot of situations where automated testing can be useful.
Just think about how often someone broke a test in the past which caused a lot of unnecessary noise on IRC when this person could just have fixed it an hour after breaking it and nobody would have noticed.
I you have some time I recommend watching this video, it explains the topic quite well in my optinion (the general part in the beginning at least):
I also recommend this short and general overview of what continuous integration means:
I have started experimenting a bit with Jenkins and figuring out what can be done and what could be useful for us.
Here's what I have so far:
Basic building and testing procedure:
- Jenkins checks for new svn revisions every 10 minutes. It uses svn update for the checkout instead of doing a fresh checkout everytime.
- Runs update-workspaces.sh with the newly introduced option "--jenkins-tests"
- Runs make
- Runs our test executable and redirects the output to an xml file.
- Fixes a little incompatibility with the XML schema with sed and then uses the generated XML to display the results of the tests
These steps get exectued for both debug and release configurations.
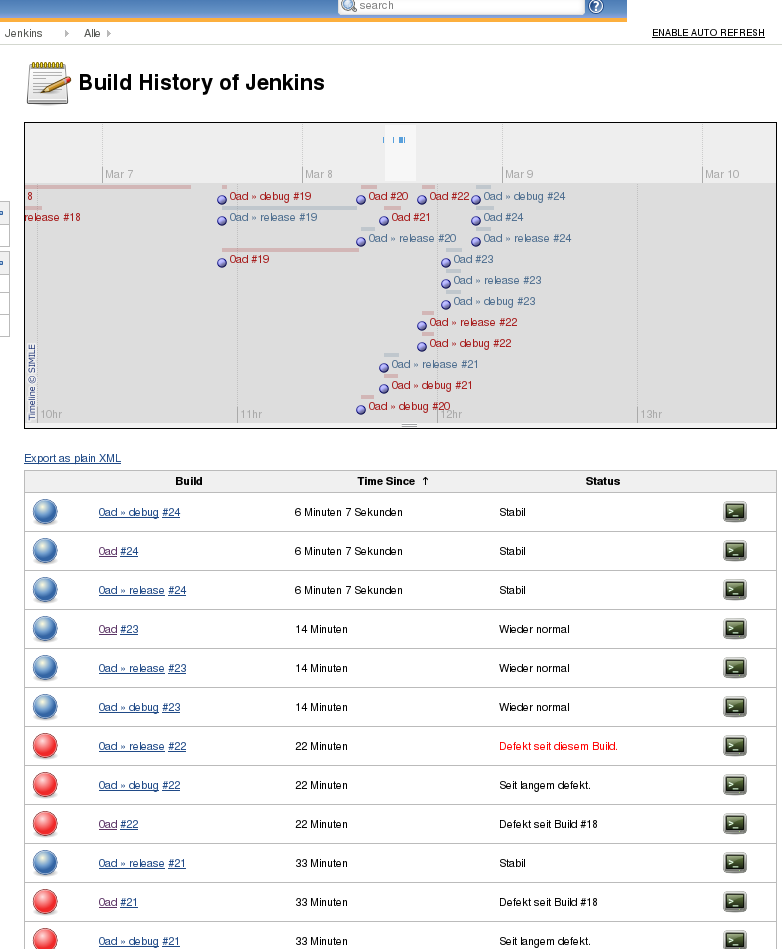
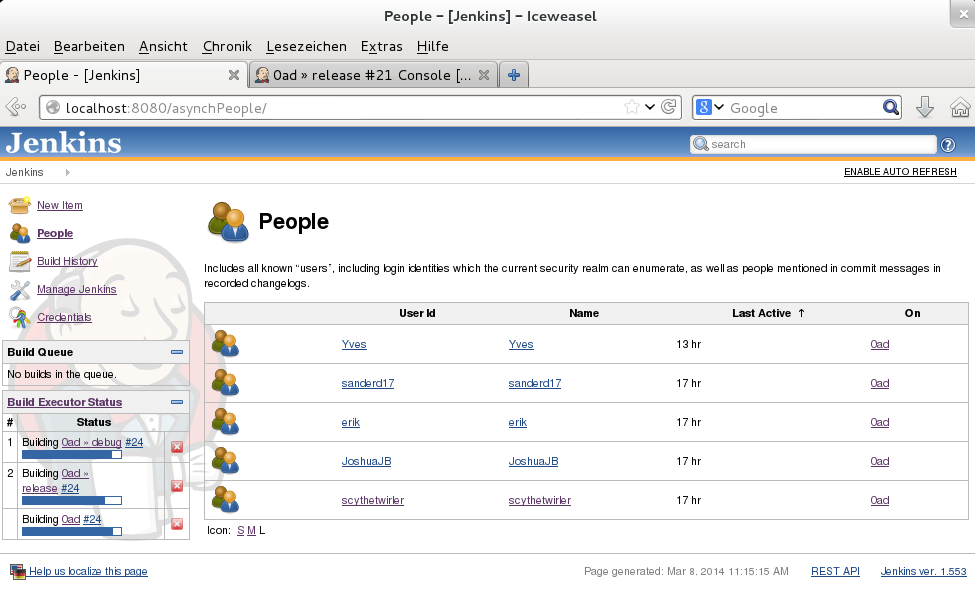
Jenkins has a web GUI which displays and visualizes all kinds of useful information.
Unfortunately I don't have a DMZ setup at home, so I don't want to make the server accessible to the internet.
But I've made some screenshots to give you an impression of how it looks:
This is the overview showing a trend (currently a dark cloud because many builds failed while I was testing).
On the bottom left corner you see build with two different configurations (debug and release) running.
Here you see the tests listed. They all passed in this run.
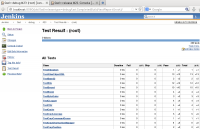
There are also nice graphs showing a history of the tests either for all tests or individual tests.
Of course the graph is not very interesting with only two builds and 100% tests passed in both builds:
There's also a build history showing when which tests succeeded or failed:
Last but not least, Jenkins keeps track of commits and automatically adds people who do the commits to its configuration.
We could assign email addresses to people and send mails if one of their commits doesn't pass a build or a test (I heard you can do that, but I haven't tested it yet).
I'll continue improving my Jenkins setup to figure out what can be done and what's useful for us.
At some point we should probably think about configuring a Jenkins server which is accessible through the internet.
At the moment this would be too early IMO. I know that Philip already has a sever, but as far as I know he only uses it for building and hasn't integrated tests or anything like that.
-
7
-
Do I have to change from this module pattern? It is excellent!
No, I'm quite sure this module pattern will continue to work in the future because it doesn't use special Javascript features or anything like that.
The pattern is so commonly used that it will have to be supported for future versions.
With the ES6 specification they even try to integrate the idea of modules directly into the language.
So maybe we could simplify the notation or get some additional benefits at some point. I haven't yet checked how this new type of modules will work exactly.
Get some information about these new modules here.
And what is the issue with the debugger? It might save me some time, so if there is anything I can do except compiling, let me know.
The issue is that the C++ debugger API changed even more than the rest of the JSAPI and the whole server component of the debugger has to be rewritten.
There's a Javascript API which is more stable and it would probably be a good idea to use that instead.
I also wondered if there would be a way to somehow connect existing debuggers more directly to avoid maintenance work, get additional features and have a UI that people are already used to.
-
1
-
-
This means the SpiderMonkey is history? No more mess with it? Oh, and the JavaDebugger will work now again (if we really need it) or am I just mixing it all up again?
Yes, you're mixing it all up!
I'm upgrading SpiderMonkey, so only version 1.8.5 will be history for us.
The JS Debugger will have to be reimplemented with the new version, that task isn't part of the upgrade.
The upgrade isn't done yet but it's close to completion.
After this upgrade we'll already have to start with the next one. It should be much easier now but there are still some time consuming tasks involved like preparing for exact stack rooting and a moving garbage collector.
-
Problem solved!
It looks like a bug in VisualStudio, but passing the JS::Value as reference instead of using a return value works around the problem.
It was a bit of work to adjust all implementations of ToJSVal and change all call-sites, but I don't see any disadvantages for the final result.
I've registered at Github too and created a branch for the SpiderMonkey upgrade.
You can get it here: https://github.com/Yves-G/0ad
It should build as normal on Windows and Linux now and shouldn't require any additional steps. Feedback is appreciated but be aware that it still contains some known issues too.
EDIT: On Linux you need to install libnspr-dev
-
2
-
-
Philip said he had a similar issue with VS2008 when upgrading to SpiderMonkey 1.8.5.
He had to define JS_NO_JSVAL_JSID_STRUCT_TYPES and build SpiderMonkey with that definition on Windows.
I've tried this now but unfortunately it doesn't work here.
During testing I noticed that the error only happens in debug mode in my example program. In 0 A.D. it happens in release and debug mode though.
I've asked on the SpiderMonkey newsgroup.
I also found something interesting about the different ways the function is called here.
The return value is saved depending on its size:
32-bit or smaller values
Widened to 32 bits and stored in the EAX register
64-bit values
Stored in the EDX:EAX register-pair
Values larger than 64 bits
Stored in memory, which EAX then points to.The working version uses the convention for values larger than 8 Bytes / 64 bits.
The segfault-version uses the convention for 64 bit values.
It still looks like the first version only reads 8 bytes though (otherwise it would need more lines that copy from an offset of eax like eax+8 and eax+12):
004117FC: 8B 10 mov edx,dword ptr [eax] ; expect the pointer to the JS::Value data in eax. Copy the first four Bytes to edx 004117FE: 8B 40 04 mov eax,dword ptr [eax+4] ; expect the pointer to the JS::Value data in each. Copy the second four Bytes to eax
-
1
-
-
I'm analyzing the generated assembler code in the .exe now.
I'm new to assembler but what I see so far is that it calls the same function differently which must be the reason why it fails.
I hope my interpretation (comments) is correct.
This is how it calls the function in the working version:
Working 004117E9: 8D 45 A0 lea eax,[ebp-60h] ; storing a reference to the memory location of the integer argument in eax 004117EC: 50 push eax ; pushing the content of eax on the stack 004117ED: 8D 8D D0 FE FF FF lea ecx,[ebp-130h] ; storing a reference to the memory location of the JS::Value in ecx 004117F3: 51 push ecx ; pushing the content of ecx on the stack 004117F4: E8 7A F8 FF FF call @ILT+110(??$myToJSValStaticTemplate@H@ScriptInterface@@SA?AVValue@JS@@ABH@Z) ; call the function 004117F9: 83 C4 08 add esp,8 ; clean up the space required for the arguments (the int ptr and the JS::Value pointer) 004117FC: 8B 10 mov edx,dword ptr [eax] ; expect the pointer to the JS::Value data in eax. Copy the first four Bytes to edx 004117FE: 8B 40 04 mov eax,dword ptr [eax+4] ; expect the pointer to the JS::Value data in each. Copy the second four Bytes to eax 00411801: 89 55 AC mov dword ptr [ebp-54h],edx ; copy the first part of the value from the register to the memory location of the JS::Value 00411804: 89 45 B0 mov dword ptr [ebp-50h],eax ; copy the second part of the value from the register to the memory location of the JS::Value 00411807: C7 45 FC FF FF FF mov dword ptr [ebp-4],0FFFFFFFFh
And here's the segfault version:
Segfault 004117E9: 8D 45 A0 lea eax,[ebp-60h] ; storing a reference to the memory location of the integer argument in eax 004117EC: 50 push eax ; pushing the content of eax on the stack 004117ED: E8 81 F8 FF FF call @ILT+110(??$myToJSValStaticTemplate@H@ScriptInterface@@SA?AVValue@JS@@ABH@Z) ; Call the function 004117F2: 83 C4 04 add esp,4 ; clean up the space required for the argument (the int ptr in eax) 004117F5: 89 85 D0 FE FF FF mov dword ptr [ebp-130h],eax ; JS::Value structure is 8 Bytes. Expect to find the first four bytes of the JS::Value data in eax and copy it to memory (12Ch is 4 bytes before/after 130h) 004117FB: 89 95 D4 FE FF FF mov dword ptr [ebp-12Ch],edx ; expect the second four bytes of JS::Value data in edx and copy it to memory (12Ch is 4 bytes before/after 130h) 00411801: 8B 8D D0 FE FF FF mov ecx,dword ptr [ebp-130h] 00411807: 89 4D AC mov dword ptr [ebp-54h],ecx 0041180A: 8B 95 D4 FE FF FF mov edx,dword ptr [ebp-12Ch] 00411810: 89 55 B0 mov dword ptr [ebp-50h],edx 00411813: C7 45 FC FF FF FF mov dword ptr [ebp-4],0FFFFFFFFh
-
I'm still trying to understand this problem.
I don't see any static data members, so the explanation probably doesn't apply completely.
It must be releated to static function templates though because placing that code in main.cpp solved it.
Also JS::Value must be related in some way because I couldn't find any other types that cause the same problem when used as return value.
-
Using static and template induces implicite instantiation. There the compiler doesn't use a specific order and it's completely random order of instantiation and even differs from compiler to compiler (so Visual Studio compiler or GCC or whatever you use ...).
A solution could be to explicitely declare all participants in any source-file similar to:
template<>jsval ScriptInterface::myToJSValStaticTemplate<int>;
Indeed, it finally works!
Adding this line to main.cpp (in the example) solves the problem:
template jsval ScriptInterface::myToJSValStaticTemplate<int>(const int& val);
Thanks very much, you just made my day! I was staring at Visual Studio's memory view and comparing values and addresses on the stack for way too long now!
I still don't quite understand why this causes a segfault and not a compiler error. I also don't understand why it worked with SpiderMonkey 1.8.5 but not with v24.
I guess I have to read a bit more about how templates work.
-
I have a very strange problem on Windows. Maybe someone has an idea what it could be.
I have a static lib project with the two ScriptInterface files and a main .exe project with main.cpp.
Now it segfaults on the line "int x= val" when ScriptInterface is in another translation unit (the lib) AND the function uses jsval as return type AND the function is static AND the function uses a template (also check the comments in main.cpp to see which variations work and which don't).
Any ideas?
Main.cpp
#include <iostream>#include <fstream>#include <streambuf>#include <sstream>#include <stdio.h>#include "../staticlib1/ScriptInterface.h"#define __STDC_LIMIT_MACROS#include <stdint.h>using namespace std;/* The class of the global object. */static JSClass global_class = { "global", JSCLASS_GLOBAL_FLAGS, JS_PropertyStub, JS_DeletePropertyStub, JS_PropertyStub, JS_StrictPropertyStub, JS_EnumerateStub, JS_ResolveStub, JS_ConvertStub, NULL, JSCLASS_NO_OPTIONAL_MEMBERS };/* The error reporter callback. */void reportError(JSContext *cx, const char *message, JSErrorReport *report) { fprintf(stderr, "%s:%u:%s\n", report->filename ? report->filename : "<no filename="">", (unsigned int) report->lineno, message);}void initContext(JSContext* cx){ uint32_t options = 0; options |= JSOPTION_EXTRA_WARNINGS; // "warn on dubious practice" options |= JSOPTION_VAROBJFIX; // "recommended" (fixes variable scoping) options |= JSOPTION_BASELINE; options |= JSOPTION_ION; options |= JSOPTION_TYPE_INFERENCE; options |= JSOPTION_COMPILE_N_GO; options |= JSOPTION_STRICT_MODE; JS_SetOptions(cx, options); JS_SetErrorReporter(cx, reportError);}int main(int argc, const char *argv[]) { JSRuntime* rt = JS_NewRuntime(16 * 1024 * 1024, JS_NO_HELPER_THREADS); JS_SetNativeStackQuota(rt, 128 * sizeof(size_t) * 1024); JSContext* cx = JS_NewContext(rt, 8192); JSAutoRequest rq(cx); JSObject* global = JS_NewGlobalObject(cx, &global_class, NULL); JSCompartment* comp = JS_EnterCompartment(cx, global); JS_SetGlobalObject(cx, global); JS_InitStandardClasses(cx, global); initContext(cx); ScriptInterface scriptInterface; jsval value = scriptInterface.myToJSVal(188); // works value = ScriptInterface::myToJSValStatic(188); // works ScriptInterface::myVoidStaticTemplate(188); // works value = ScriptInterface::myToJSValStaticTemplate(188); // segfault}ScriptInterface.h:
#ifdef _WIN32# define XP_WIN# ifndef WIN32# define WIN32 // SpiderMonkey expects this# endif#endif#include "jsapi.h"class ScriptInterface{public: ScriptInterface() {}; template<typename T> jsval myToJSVal(const T& val); template<typename T> static jsval myToJSValStaticTemplate(const T& val); static jsval myToJSValStatic(const int& val); template<typename T> static void myVoidStaticTemplate(const T& val);};ScriptInterface.cpp:
#include "ScriptInterface.h"template<> jsval ScriptInterface::myToJSVal<int>(const int& val){ int x = val; printf("value: %d", x); return JS::Int32Value(x);}jsval ScriptInterface::myToJSValStatic(const int& val){ int x = val; printf("value: %d", x); return JS::Int32Value(x);}template<> jsval ScriptInterface::myToJSValStaticTemplate<int>(const int& val){ int x = val; printf("value: %d", x); return JS::Int32Value(x);}template<> void ScriptInterface::myVoidStaticTemplate<int>(const int& val){ int x = val; printf("value: %d", x);}

SpiderMonkey ESR31 upgrade
in Game Development & Technical Discussion
Posted
Scripting allows features like automatic downloads of maps, missions and even AI scripts or GUI mods.
We can still restrict this to allow some of these types, but compared to compiled native code it can be delivered over the web in a relatively secure and fully portable way.
I don't see how this could be achieved by C++. C++ code is always compiled for a specific target platform (you can't load a .dll from Linux). Also it would be quite hard or impossible to limit the possibilities and make executing untrusted code relatively secure.
0 A.D. has always been designed for modding and scripting is also important to lower the barrier for new modders. C++ is not the preferred language for modding because it's quite hard to learn and easy to introduce bugs.
I'm quite sure we find a solution with Javascript. Part one of the plan is figuring out how far we can push Javascript performance and where the limit is.
The second part is finding solutions for these limits like providing native C++ functions for the scripts.