

Ykkrosh
-
Posts
4.928 -
Joined
-
Last visited
-
Days Won
6
Posts posted by Ykkrosh
-
-
The replay code should be perfectly robust in theory (i.e. it might have bugs, but I'm not currently aware of any). The game can output a hash of the simulation state into its recorded commands.txt (should do it by default in multiplayer; for single-player you'd have to enable it in CNetLocalTurnManager::NotifyFinishedUpdate), and CReplayPlayer::Replay will check those hashes (remove the "if (turn % 100 == 0)" line to make it go slower but report any divergence earlier), so that should tell you if the behaviour isn't replayed perfectly.
If the hashes don't match then something is broken. To debug it, you'd need to enable m_EnableOOSLog in CSimulation2Impl::CSimulation2Impl, which will output the serialised state after every turn (into logs/sim_log/$PID/). Do that with the normal game where you're recording the commands, and again with the replay, and then find the first turn where the output differs and do a diff of the .txt files to see what part of the state is differing. Hopefully that'd indicate where to look

The simulation RNG (CComponentManager::m_RNG) doesn't get seeded at all, so it should be consistent for every run.
-
The game can't compile as 64-bit on Windows currently - it'll take quite a bit of effort to set that up (particularly recompiling all the third-party libraries we use), and the difference in performance is likely to be negligible, so it doesn't seem worthwhile.
(We do support 64-bit builds on Linux, so the game itself should be portable, but it's more of a pain to set up on Windows.)
-
When it says "Working copy 'C:\0AD' locked.", that means it thinks TortoiseSVN is already running there. If it's definitely not (i.e. you're not accidentally doing two updates or checkouts simultaneously), then it's just confused (which is fairly common), so you should select the TortoiseSVN -> Clean Up option to get it back to a working state, and then do another SVN Update and it should continue the downloads, hopefully.
-
It will not clutter the main news page, and I can provide links on Facebook & Twitter for visibility.
Fans love these nitty-gritty updates.
Okay, sounds good. Can someone help me figure out the details of what needs to be done?
(like how/where/who/when to publish stuff, and what surrounding text/graphics/etc to use to make it look pretty while begging for money, etc)the last couple of days Philip has been reviewing code other people has submitted (when he did the final work on his thesis he didn't have time to do that, so the backlog was pretty big), once he's done with that he'll continue working on writing new codeYeah, I'd got up to about 800 unread messages from Trac (notifications of ticket comments or SVN commits which I needed to read and maybe respond to); now it's back down to 12. So now I started reviewing some of the complicated patches, and will post another progress report once I've done a day's worth of that reviewing.
probably sometimes reviewing patches is more difficult than write new code :-)I think it is
 . To be confident that a patch will work and won't have problems that cancel out its value, I generally want to understand the area of code that's being changed (which I might not have looked at since a year ago so it takes a while to re-learn), and then understand the patch itself, and then try to work out other solutions to the same problem to be reasonably sure that the patch is a sufficiently good solution. Those are quite similar steps to when I'm writing code myself, so reviewing patches isn't hugely easier, though on average it's still good to have more people involved and providing more ideas and patches
. To be confident that a patch will work and won't have problems that cancel out its value, I generally want to understand the area of code that's being changed (which I might not have looked at since a year ago so it takes a while to re-learn), and then understand the patch itself, and then try to work out other solutions to the same problem to be reasonably sure that the patch is a sufficiently good solution. Those are quite similar steps to when I'm writing code myself, so reviewing patches isn't hugely easier, though on average it's still good to have more people involved and providing more ideas and patches -
As Erik said, there's been some people who've been official members but haven't actually done anything (for various reasons), and I think it seems fairer to only list people who've contributed usefully, so it may be good to record pointers to at least one significant commit from each person (or patches committed on their behalf) (or forum posts etc for designers and concept artists etc who haven't committed stuff) to verify that. ("significant" is kind of a judgement call - I probably wouldn't count r10494 but would count e.g. r10531.) But I don't think we should try to differentiate based on exactly how much work each person has done (since it's generally impossible to quantify and not particularly important) so we don't need to record that much more detail.
I believe contributors.txt was accurate as of the time it was last updated, but is somewhat outdated now, and it only counts source/ (not programming in JS, or any non-programming work). Also it only records real names, not nicknames, since WFG originally had a real-names policy for members (to encourage a more professional and less impersonal community, I guess), but that doesn't work well with open source contributors so I'm not sure of the best approach.
Listing donators in the credits seems good, where people have said they're happy to be non-anonymous.
-
Yeah, there's no point buying expensive hardware if applications don't try to use it as much as they can to go as fast as they can
. (The important thing is that they scale back to still work acceptably on older/cheaper hardware.) -
Day still-not-counted
Mostly finished playing around the GPU profiling code.
Committed it to SVN - if you want to try it (and your graphics drivers provide GL_ARB_timer_query, GL_EXT_timer_query, or GL_INTEL_performance_queries - most NVIDIA/AMD cards (with proprietary drivers if on Linux) should have the first two), you can launch the game, press F11 (which now enables the GPU profiler too), wait a while, then use profiler2.html, and it should have an extra row for the GPU data.
With an NVIDIA GPU (GTX 560 Ti) I get:

First coloured row is CPU, second (empty) row is some other thread, third row is GL_ARB_timer_query output, fourth is GL_EXT_timer_query. The difference is that the ARB one is aligned correctly relative to the CPU, whereas the EXT one isn't (it can only measure durations, it can't tell when the frame started rendering except by guessing), so the EXT one is not smoothly spaced and sometimes overlaps itself.
In the CPU row, the cyan box underneath "water reflections" represents a piece of code that's reading a bit of data back from the graphics drivers. That's a fast operation, but it looks like the NVIDIA drivers are taking it as an opportunity to delay the CPU - otherwise the CPU would continue generating frames faster than the GPU can render them, so the delay is just to stop the GPU falling too far behind.
Each frame is about 8 msec long, which corresponds to 120fps, which is plenty, and this is with 32x AA and 16x AF, so graphics performance isn't a problem on this kind of hardware.
With an Intel GPU (HD Graphics 3000) I get:

Average framerate is about 30fps, which isn't great, so optimisations for this kind of hardware would be worthwhile.
It doesn't have GL_*_timer_query but it does have GL_INTEL_performance_queries. That gives similar timing data as GL_EXT_timer_query (including the problem with frames overlapping each other because it can't tell when they start rendering). But it also gives a load of extra counters - the yellow box is a tooltip on the "patches" (terrain rendering) region of frame 265. It shows that e.g. we rendered 17876 triangles ("PrimitivesCount"), with 1.4 million pixels generated ("FragmentsRendered"), but about 10 million pixels of texture data were read ("SamplerPostFilteredTexels"), and the texture-reading hardware was busiest ("SamplerBusyTime: 0.986..."), which sounds like it might be the primary thing affecting the overall rendering performance. Would need to do a lot more work to fully understand and optimise rendering performance in this case, but at least it gives a bit of an idea about what to look into first.
Now I really ought to get back to some properly useful work...
-
maybe you can also automatically start a browser
Sounds like a good idea. Maybe I should change F11 to toggle a profiler menu screen, saying like "1: Hierarchical profiler. 2: Renderer stats. 3: Network stats. 4: Enable profiler2. 5: Open profiler2 visualiser.", so you can select what you want instead of hitting F11 lots of times to cycle through the modes, or something like that. (But I really need a better name than "profiler2"
)Also the framerate (with SHIFT-F) varies too fast and is hardly readable. Maybe it should update less often, or eventually using a moving average.In theory it is a smoothed average (using an IIR filter), judging by the code. It does seem pretty terrible in practice, though - not sure why but it'd be good to fix
The simupdate regularly freezes my game for a second or something.Sounds like AI.
Should I click on profiler2.html while running 0 A.D. ? cause i ran it after shutting down the game.Yes - it connects to the game via HTTP to download the current data, and doesn't store it on disk anywhere, so it won't work after shutting down. (Ideally it would be possible to save the profiling data to disk and load it later, or upload it and share with other developers, etc, but I haven't tried that yet.)
(Just out of curiosity: What PhD programme did you do?)(It was some computer science stuff, to do with implementing routing protocols based on algebraic models.)
Last time it was more like "we need 3000 bucks to hire someone" and it took you quite some time to announce publicly who that would be in the first place.Yeah, it was anticipated to be sooner but it took longer than hoped to finish my PhD, and nobody else argued strongly for doing the work themselves in the meantime, so it's been quite delayed
(and we didn't want to publicly announce details until being fairly sure they were going to be correct)Well you could reveal a bit more about how the whole idea of fundraising startedThe history is basically that k776 suggested in #0ad-dev that I could work on the game for a year after finishing my PhD, given his good experiences with hiring a developer on Globulation 2, so he set up the Pledgie thing for $45K for a year's work (based on a roughly typical starting salary for software developers in the USA/UK/etc part of the world) for me or any other developer we'd think was appropriate, then the next day it was argued that $45K was insane so it was changed to $3000 for 1 month as a nice round figure, and that's about it
. (It's less than I'd expect to get when starting a proper job, but (despite tax) more than I got as a PhD student, so it lets me wait and spend time on the game before getting a real life.)how many hours 3000$ correspond to160 hours (8 hours/day * 5 days/week * 4 weeks/month) though I'm not sure where that's stated explicitly.
what about more posts and updates about this on moddb? It might raise awareness around the second pledgie campaign.Yeah, I've been trying to get the hang of doing some videos and diagrams and explanations in this thread, but it's not an ideal place since few players will see it. Do you think these sort-of-daily progress reports would be suitable for ModDB, or would some changes to structure or style or content etc make them better? (and/or would some kind of new WFG developer blog be worthwhile for this? (Don't really want to clutter up the main news page, but ModDB seems slow at updates so maybe best not to use them exclusively.))
-
I doubt MinGW would work since our Windows-specific code almost certainly assumes it's being compiled with MSVC. I'm not aware of any benefits of compiling with GCC instead of MSVC, so it doesn't seem worth spending any effort making the game compatible with GCC on Windows.
-
Since the engine is under the GPL license, you're allowed to modify and sell it but you have to make the source code of your modified version freely available.
(If you create new art from scratch then you can use that art under a non-open-source license with the game engine, so the game package as a whole can forbid copying, but the engine itself must remain open source.)
-
1) the profiler server starts when pressing F11 but can no longer be stopped?
Correct. This is probably all temporary though - I'll add some config variables and/or other ways to control the profiling.
the test failsFixed.
I was just wondering... I know the engine has been in development for years, however I can't help but feel you might benefit from switching to a ready-made engine.We've not seen any engines that would be suitable (open source, capable of supporting all the features we want, better than what we've currently got, etc). Even if there was one, it would generally be far more expensive in time and effort to adopt a radical change than to continue incrementally improving what we've already got (assuming what we've already got is capable of being extended to what we want, which I believe it is
). -
Okay, I'll try to update that within the next few days (when the profiler design is a bit more stable) - please remind me if I forget thenJust as a reminder, please keep the "EngineProfiling" wiki page up to date when integrated. It is an awsome wikipage
Currently I'm only thinking of the short pathfinder, so it shouldn't affect that.While talking about optimization, on the first post you talk about optimizing the pathfinder. Do you think your changes will impact the long pathfinder ? I am still musing about implementing hpa* whereas I terribly lack time. Note that it is just a question, not a request, your work is awsome and I lack time
Yeah, I'm currently using Windows. I started with the ARB_timer_query because it's more powerful than EXT_timer_query - the EXT one can only measure relative times, not absolute times, so it can say how long each part of the rendering takes but can't say how far it's delayed behind the CPU, so you can't line the CPU and GPU up properly. But INTEL_performance_query has the same problem with only providing relative times, so I need to deal with that anyway, so I suppose I might as well add EXT_timer_query too. (Currently my GPU-timing code is hideous so I need to rewrite it all anywayDid you try it on Windows? On mesa drivers (intel included) there is some support for timer_query (EXT variant))
-
Day 6 plus a half
(This was Thursday, but I got a bit distracted and failed to post here earlier.)
Did some more work on the profiler, primarily fixing some bugs and cleaning up code enough to commit it (here/here/here).
If anyone wants to test it, you should recompile the game then launch it and press F11 to enable the new profiler's HTTP output (it's disabled by default for performance and security), then open the file source/tools/profiler2/profiler2.html in a web browser. (I've only tested Firefox 7; browser compatibility isn't a priority). Then it should work, with luck.
One extra feature is that the code can add text annotations to each profile region, which are displayed as tooltips:
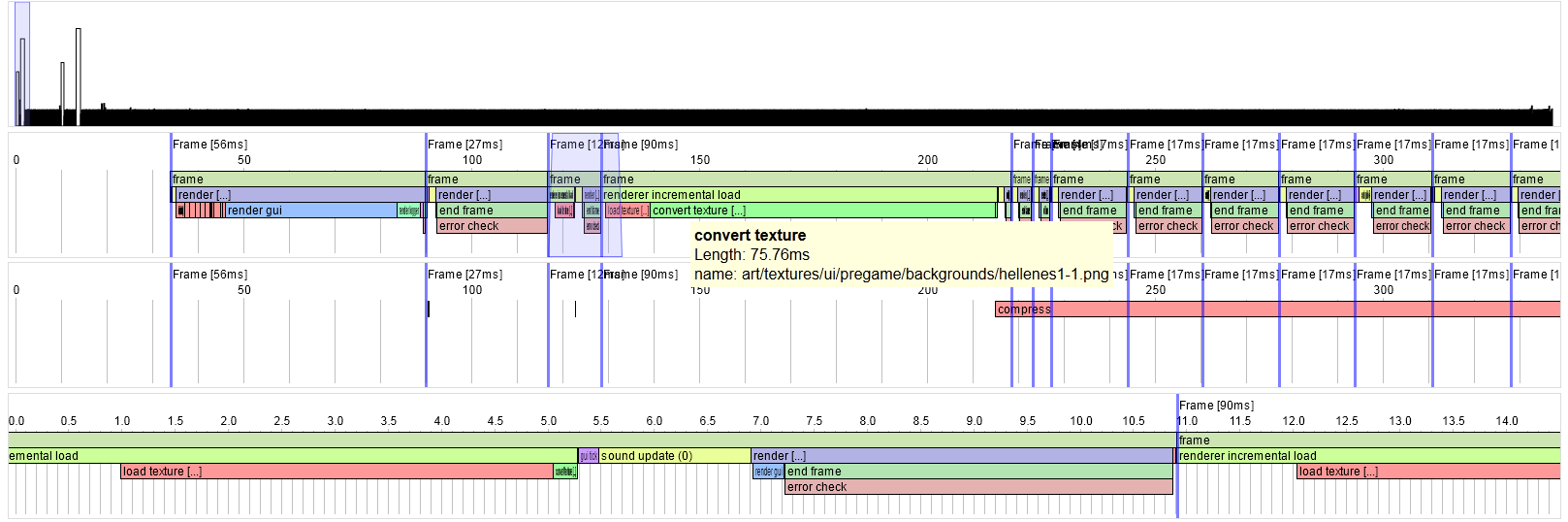
Holding the mouse over the "convert texture [...]" region pops up the box saying which texture it's converting. The "compress" in this image is happening in a secondary thread, so it overlaps many frames. (In practice the compression is done before running the game and cached, so this isn't normally a real slowdown). I think this makes it particularly useful for improving the game's startup/load performance, since we can see what files are taking a long time when they're first loaded.
Day not-counted
I subsequently played around with a few more things (not committed yet), mostly for fun rather than to be useful for the game, so they don't count as proper work. In particular, the profiler can display the GPU like a separate thread (using the GL_ARB_timer_query extension, supported on most NVIDIA and ATI/AMD cards with the proprietary drivers):
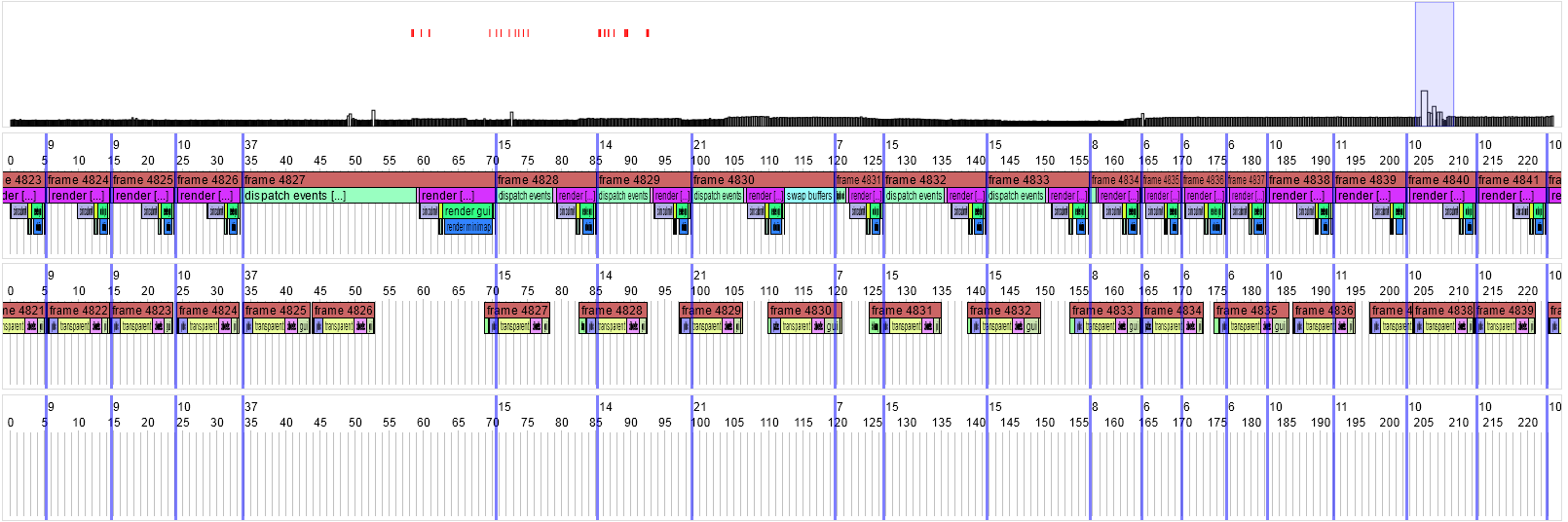
Here the CPU is the top group of coloured boxes, the GPU is the bottom group. This gives a nice view of the fancy things that graphics drivers do. At the start of the timeline (on the left), the CPU is rendering frame 4824 while the GPU is rendering frame 4822. That means the CPU is submitting a load of rendering commands, which get queued up for 10-20msec before the GPU (which is busy rendering an earlier frame) gets around to processing those commands and doing the actual rendering. On frame 4827 I did something to delay the CPU a bit. The GPU carried on rendering the queued frames, but then had to pause until frame 4827 was ready to render. After that, the CPU and GPU times wobble around a bit (but the GPU maintains a fairly smooth framerate) until the GPU has synchronised back to 2 frames behind the CPU.
One annoyance is that Intel drivers don't support GL_ARB_timer_query, and Intel GPUs are where optimisation matters most (since they're so slow). It turns out that the most recent ones have an extension called GL_INTEL_performance_queries, which sounded interesting, but there's no specification and it seems nobody has ever written anything about it. So I fiddled with it a bit and wrote some documentation of the extension. Not sure it's hugely useful, but at least it can give a reasonable indication of the time the GPU spends on each part of the rendering. (It only gives relative times, not absolute, so unfortunately it messes up the timeline view a bit, but it's better than nothing.)
-
Day 5
Now working on improved support for performance profiling.
There are lots of parts of the code that need optimisation to make them faster, but I don't think our current tools are good enough for accurately measuring and visualising the important aspects of performance. In particular, the current in-game profiler (press F11 and digit keys when running the game) is designed to show an instantaneous view of the average performance over a number of frames. Similarly, typical third-party profiling tools (CodeAnalyst, Callgrind, etc) show an average over a long period time. That's fine for applications where you only care about overall throughput (e.g. how many seconds it takes to encode a video file), but for games we also care about consistency of framerate. If a game runs at 60fps but then pauses for 100msecs once per second, that's worse than running at a smooth 30fps. Similarly, it might pause for a second once every few minutes (perhaps when loading some new data from disk). We need a way to detect that kind of inconsistency and to understand what caused it.
One way to smooth out the framerate is to run slow tasks in a separate thread, so they don't interrupt the flow of the main rendering loop. As a bonus, that also improves throughput for users with multi-core CPUs. The current in-game profiler can't cope with multi-threading at all, so we need to fix that too.
I was pointed at the RAD Telemetry tool, which appears to be designed to solve exactly this problem. It's $6000 and not open source, so we can't use it for our game, but it's a good demonstration of the features that would be useful.
So I started writing a new profiler. It collects and stores timing data from the engine (without doing any averaging across frames), then you can visualise and analyse the data in a web browser.
(Technical details: Each thread has a ring buffer, into which it writes a series of events (frame starts, entering named region, leaving named region, etc). An embedded Mongoose server provides an HTTP interface: an HTML page requests the data from the engine, so the engine grabs a copy of all those ring buffers and converts them to JSON and returns them. The HTML page then processes the data and renders it onto canvases.)
The current status is that it looks like:
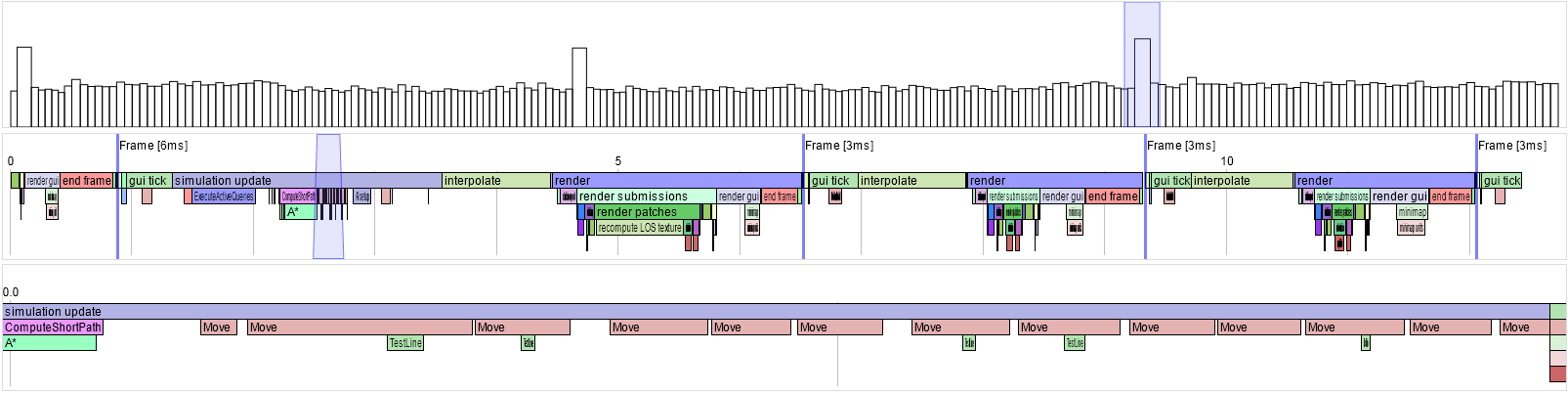
The top section shows the length of each frame. The blue box is expanded into the middle section, which shows the named regions. In this example it's clear that the occasional spikes are caused by the "simulation update" region (which doesn't happen on every frame). The blue box in the middle is expanded into the bottom, showing a lot of "Move" regions taking up some of the time.
I think this is almost useful now - I'm planning to spend the next day making it a bit more powerful and cleaning up the code, and then it should be ready to help with some optimisation work.
-
Currently it doesn't attempt to handle incompatible versions sensibly. If you're joining a new multiplayer game, you'll probably just get an out-of-sync error. If you're loading a saved game, you may get errors saying the file is corrupted (or actually I think it might just crash) or may get script errors or the game may just run a bit weirdly (e.g. if you changed a unit's max HP after saving, then load the earlier game with that unit, its max HP will have changed but its current HP won't have, so it'll look more injured than it used to).
For now, I think we ought to make it compute some kind of checksum of all the simulation data files and use that in saved games and in multiplayer sessions. If the data files have changed at all, it will notice and can warn you that the game probably won't work. (But it should allow you to override that warning since developers might be intentionally changing their data files to test stuff). In the future it would be nice if saved games were compatible across new releases of the game, but that's probably not worth implementing yet, so players will just have to restart if they update the game.
-
Day 4
I fixed the known problems with the LOS calculation and other saving-related bugs (player colours, unit animations, etc), and cleaned up the GUI when reconnecting (it now goes straight to the loading screen and tells other players that someone has joined), which is kind of tedious but necessary. Now it just needs people to test it to find out what else is broken
Perhaps more excitingly, I also added some code for saving and loading single-player games:
The GUI is pretty basic at the moment, and the saved games are a bit fragile (it doesn't work if you have AI players, and it'll likely get confused if you update the game's data files and then use an old saved game), but otherwise it seems to be working okay.
-
Is the reported failure (apic.cpp line 134 in your original post) the line that says
return ApicIdFromIndex(processorApicIds, processor);
in the version you're compiling?
What version of GCC are you using? (run "gcc -v")
Could you run "make lowlevel verbose=1", find the part of the output where it refers to apic.cpp like
apic.cpp
g++ -Iobj/lowlevel_Release -include obj/lowlevel_Release/precompiled.h -MMD -MP -DNDEBUG -DCONFIG_FINAL=1 -DLIB_STATIC_LINK -DUSING_PCH -I/usr/X11R6/include/X11 -I/usr/X11R6/include -I/usr/include/X11 -I../../../source/pch/lowlevel -I../../../source -I../../../libraries/valgrind/include -I../../../libraries/cxxtest/include -g -Wall -O3 -Wno-switch -Wno-reorder -Wno-invalid-offsetof -Wextra -Wno-missing-field-initializers -Wunused-parameter -Wredundant-decls -Wnon-virtual-dtor -Wundef -fstack-protector-all -D_FORTIFY_SOURCE=2 -fstrict-aliasing -fpch-preprocess -msse -fno-omit-frame-pointer -fvisibility=hidden `sdl-config --cflags` -MF obj/lowlevel_Release/apic.d -MT "obj/lowlevel_Release/apic.o" -o "obj/lowlevel_Release/apic.o" -c "../../../source/lib/sysdep/arch/x86_x64/apic.cpp"and post here exactly what it says in your version?
Then, could you take that command (starting from the "g++"), add a "-E" to the end, run it (from the workspaces/gcc directory), then get obj/lowlevel_Release/apic.o (which should be a text file, not binary) and upload/attach/pastebin/etc it?
(I'm wondering if there's something weird in your environment that's defining a macro named "processor", because I don't see how else that code could fail, though then I don't see how some earlier code would succeed. In any case, hopefully the above would either show or rule out that problem
) -
Aside from fixing the algorithm to be consistent, how about when a player reconnects, have all players trigger a recompute of LoS, so they all get the freshest LoS possible?
That sounds kind of like an ugly hack, and if the bugs are fixed properly then it won't be necessary, so I think it's better to just fix the bugs properly
. Currently the simulation code doesn't even know that a player has reconnected (that's handled purely by the network server code), and it would add non-trivial complexity to have the simulation depend on that information (since it'd be a new input channel that would have to be synchronised over the network, stored in replays, tested, etc), so I think that general kind of thing should be avoided if possible. -
Day 3
Cleaned up the code for handling reconnection, and tested it over the internet with some people. The reconnection seemed to work fine - the only bugs found were in the saving/loading code.
The trickiest bugs are in the code that handles line-of-sight calculations (i.e. revealing the map and pushing back the fog-of-war when in the vision range of a unit). The basic idea is that the code has a 2D grid counting how many units can see the corner of each tile:
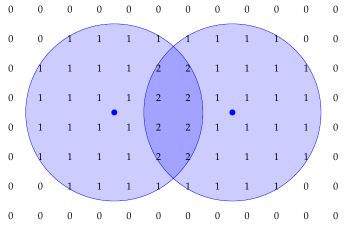
The two blue units (with vision range represented as the large circles) are close together, so some tiles are visible to both units and some to only one. If a tile is in range of at least one unit, then it should be visible to the player, else it'll be fog-of-war or shroud-of-darkness.
In the real game, the vision ranges might have a radius of perhaps 16 tiles, and there might be a thousand units on the map. Computing the counts for every visible tile for every unit would be pretty slow - there's just too much data to process. To keep the game running fast, we only compute the whole visibility-count grid at the start of the game, and then update it incrementally as units move around the map.
For example, consider a unit moving from the red position to the green position:
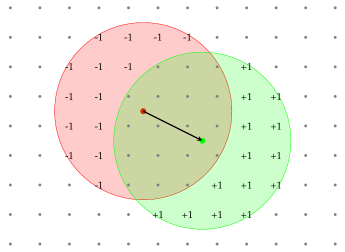
We're interested in the changes to the values in the visibility-count grid, rather than the absolute values. We just need to subtract 1 from the count for the tiles in the unit's old vision range (red), and then add 1 for the tiles in the new vision range (green), and we should end up with the same result as if we recomputed the entire grid from scratch with the unit in its new position.
Since units usually move very short distances, most tiles in the old vision range will still be in the new vision range. We'd be subtracting 1 then immediately adding 1, so we actually don't need to update them at all - only the tiles inside one range but outside the other need updating. With that optimisation, we rarely need to update more than a few dozen entries in the visibility-count grid every time a unit moves, so it's pretty fast.
The problem is that in some rare cases, the result is not the same as recomputing from scratch, due to bugs in the implementation of this algorithm. (The implementation tries to avoid the obvious approach of using square-root functions to compute the edges of circles, because square-roots are slow, so it does something a bit trickier and more error-prone.) That doesn't matter much in normal games - the bugs are largely unnoticeable - but it matters when saving/loading games for multiplayer reconnection. We don't store the visibility-count grid in the saved game file (to minimise the file size), and instead we recompute it from scratch when loading. But that means one player has the newly recomputed version, while the older players have the incrementally-computed version, and they differ. The game eventually detects that inconsistency and reports an out-of-sync error. If the error wasn't detected, perhaps one player's copy of the game would think a unit had lost its target into fog-of-war while another player thought the target was still visible, so the rest of the game could play out differently and the players would get very confused.
So I need to fix that problem now. Also the GUI needs some improvements and fixes when reconnecting, but hopefully that'll be about enough.
-
Okay, so, now this building has 1000 Loyalty. To capture it, you select a bunch of bipedal soldiers and right-click the building as if attacking it.
What if your selection includes both bipedal and siege units?
Perhaps loyalty could be linked to current hitpoints, so normal attacks (by siege units) effectively drain it too. Say the building starts with 500 hitpoints, and 1000 max loyalty. When a soldier tries to capture the building, they increase its "disloyalty points" (which decay to 0 over time if uncaptured). When disloyalty points + (max hitpoints - current hitpoints) > max loyalty, then the building is captured. I.e. you could capture the building by doing 1000 disloyalty-points of capturing; or by doing 499 hitpoints of damage plus 501 disloyalty-points of capturing. It's much easier to capture a heavily-damaged building (which makes sense since the inhabitants are frightened), and so your siege weapons can contribute to your capturing instead of being useless when you're trying to take over an enemy city, though there's a tradeoff between capture time and repair-back-to-full-health-after-capturing time. Once you've captured a building it wouldn't lose its disloyalty points, but you can quickly repair it so the enemy can't trivially recapture it, and then wait for the disloyalty to decay back to 0.
If it is a unit-training building, like a Barracks, then the new owner can only train its own units from this new Barracks.That sounds like the most complicated thing to implement for this feature (though almost certainly possible).
What happens if you capture a unit-training building for which your own civ doesn't have an equivalent (like a Celt player capturing a hele_gymnasion)?
I don't like deriving any semantics from template names, so maybe we'd need to explicitly annotate the templates with something like
<Capturable>
<CivEquivalents>
<cart>cart_barracks</cart>
<celt>celt_barracks</celt>
...
</CivEquivalents>
</Capturable>and TrainingQueue can check if the current owner's civ differs from the building's native civ, in which case it should load the corresponding CivEquivalents template and use that training queue data instead of its own (and same for research and construction), and if the current owner's civ is not listed in CivEquivalents then the captured building can't train anything at all.
Special Buildings (theatron, tacara, etc.) can only be destroyed. The only capturable buildings are the default buildings minus fortifications.Oh, okay. But we still ought to handle the case where it's captured by a civ that doesn't have an equivalent of that "default" building, since we or modders might want to add weird new civs with no barracks (maybe they only hire mercenaries, or hatch all their units from a spawning pit).
-
Day 2
Worked more on reconnection support. It's a bit more painful to implement than I hoped (the saving/loading is fine but the coordination between server and clients is already complex and this extension makes it worse). But the above
shows a fundamentally working version, which is nice. Should just need to clean up the code now, then test it more carefully and fix any remaining problems.With this example (Oasis II at the start of a match (i.e. with very few units, except for trees and animals)) the entire saved game state is only about 80KB, so it should download pretty quickly to a reconnecting player.
-
My two cents worth: Don't use just usernames to determine who to match up. Short of implementing a login system, for now, use the same ID used in profile reporting as the re-entry key. Would that work? Any big issues doing that?
What Erik said - those IDs are designed to have some limited security properties (like anonymity (or at least pseudonymity)), and reusing them in other contexts would risk weakening those properties. It'd be better to have a separate persistent ID that's designed for multiplayer usage (so e.g. you can't impersonate another player's ID, and so it could be integrated with the lobby server and rankings and global bans and whatever) so we can avoid unexpected side-effects. If we want to stop people cheating in multiplayer (e.g. connecting as other players) there's a lot more we'd need to do anyway (there's basically no security in the current implementation), so I think that should be approached as a separate task.
I guess the only "danger" is if the file transfer is really, really slow, it might not be feasible for the reconnecting player to receive the complete state and fast-forward before the game ends.Yeah, it might not be ideal if you have a dialup network connection and an extremely slow CPU. But it's probably still better to make one player wait for 5 minutes when reconnecting than to make every other player pause for 4 minutes while the first is downloading the state. (And the (compressed) state should be pretty small (maybe 100KB but I haven't measured accurately yet) so it shouldn't be too bad anyway.)
What about implementing auto save and then when a host gets a request from a player:
[...]
So on a huge map with 100's of units, if the player was only disconnected for 2-3 seconds, send the turns rather than the full map. If the turns are greater than the map size though, send the whole map (to avoid as many issues as possible).
That should work but adds a bit more complexity (e.g. making sure the player doesn't load the autosave from a different match) - it'll probably be worthwhile if disconnections are common and the simpler full resychronisation approach is too slow in practice.
-
My current plan is to do as little GUI work as possible, so I won't change how disconnections are handled - the player will get sent back to the menu screen, and the other players will carry on as normal. (We might want to change it later so e.g. the host can voluntarily pause the game if they're waiting for the player to return, and so the player gets some informative automatic reconnection screen). Then the first player can exit and restart their game if they want (it doesn't store any state on the client), and join the server's IP as normal, and if they have the same name as a previously-disconnected player then they'll be given control of that player slot. (If we had some persistent user account identifier, we should use that instead of name). Then (at least this is the theory and I think it probably should be easy enough to implement) the host will save the state at the current turn N; transmit it; the client will load the map and deserialise the state; the host will transmit the commands from other players between turn N and the new current turn M (it carries on running while transmitting); the player fast-forwards their simulation up to turn M; maybe iterate the last two steps until the player catches up completely; then the server starts accepting commands from the new player and they've been spliced back into the game.
If other games don't do this, I don't know why, because it seems obvious when you have saved games and deterministic replay
-
To be honest i don't think its worth putting much effort into reviving disrupted multiplayer games, if its any more than 2 players it becomes very difficult to get everyone ready to continue the game.
This is mainly for when a single player has lost their connection to the server - the other players carry on without them, and that player can rejoin just by connecting to the server again, so it doesn't need any complex coordination between players. That's been a fairly common situation when I've been playtesting (with WFG developers and other people on IRC) and it's a major pain to lose half an hour of progress just before you were about to launch an attack on your enemy, so it seems worthwhile spending maybe a day making it possible to recover from that situation
45 degree field of view (FOV)
in Game Development & Technical Discussion
Posted
If you double view.far or reduce view.near by half, the depth buffer resolution (i.e. smallest detectable difference between distances) is reduced by half. That can cause z-fighting problems (e.g. a building's floor flickering behind the terrain since the GPU thinks they're at the same distance), especially when zoomed out, especially for users with 16-bit depth buffers (I think most (but not all) default to 24-bit instead). So view.near should be as large as possible (and view.far as small as possible) to minimise those problems, though they probably need to be changed to avoid obvious clipping.
(If it's really a problem, I suppose we could dynamically adjust the near plane so it goes further out when the camera zooms further out, to get a better balance between resolution and non-clipping, but probably better just to stick with the static settings for now.)
Hmm, I thought I'd fixed a bug like that for Atlas, but it looks like it was this which wasn't the same. Thanks for finding this