

Thanduel
-
Posts
48 -
Joined
-
Last visited
-
Days Won
2
Posts posted by Thanduel
-
-
I've created a ticket for this and begun to work on it. So far I've just finished getting to grips with RedFox's code.
http://trac.wildfiregames.com/ticket/3362
Hopefully I'll have something useful to report back in a few weeks.
-
Despite the fact that in the example he uses stack allocation it still serves as a good illustration of the potential performance difference between normal heap allocation and a memory pool. This is because the main function of a memory pool is to return a pre-allocated memory location of a specific size. In the case of the example this performance difference is exaggerated because there is only one pool of memory to return so no logic is required to determine which pool to return but the outcome is still relevant. This is because the source of the memory for the pool is irrelevant ie stack or heap. The point is the machinery required to get memory from a pre allocated source is much faster.
In the case of 0ad you would pre-allocate a huge chunk of memory on the heap and divide it into set sizes in the initialisation. During run time the main machinery would be to pass out the next free block of a size that satisfies the memory request. This adds some logic but that logic would never be slower than a search through the heap.
-
I can't seem to connect to trac or update my svn repository. I can't even open the svn url in my browser.
-
It can be an order of magnitude faster:
http://www.codeproject.com/Articles/27487/Why-to-use-memory-pool-and-how-to-implement-it
If it were just a slight improvement it wouldn't be worth it.
C++ compilers use a general purpose allocation system that is good enough for most applications. They also provide a mechanism for people to use special purpose allocators. So for example when you instantiate an STL data structure you can pass in a custom allocator for it to use.
A memory pool system pre-allocates memory and divides it up into set sized portions that can be very quickly handed out. It allows you to circumvent the long search times for malloc to allocate memory off the heap.
-
Free cookies on Sundays.
And you can achieve much faster and much more stable allocation times for dynamic memory allocation.
-
Thanks for your response Leper. I had hoped that more work had happened behind the scenes. I think it would be a worthwhile endeavour to use a memory pooling system. It is just a mamoth task to integrate into the codebase and tune it to be the right size for the game. I'm having to work on a pure C memory pool implementation for work, perhaps I can find some overlap and contribute this. We will see.
-
Hi 0ad Devs!
About two years ago there was an attempt at converting 0ad's dynamic memory usage to a memory pool system. Eg ticket #2020 which is closed and marked wontfix.
Did anything ever come of this, I know RedFox's mega patch had to be broken up, but as far as I can see little of his code made it into the main 0ad repo. Were there specific technical reasons why this approach was rejected?
-
 1
1
-
-
Thanks for your quick response, that solves the puzzle.
-
Hi
I'm looking for some info about how the size of certain map obstructions are determined.
In the xml files associated with each map there is an entity list. Each entity points to a template. For some of these entity templates there is information about obstruction type and size. However whether a template includes obstruction information or not is fairly random. For example the apple tree template includes an obstruction type and radius but most other trees don't. Is there another place I should look for the size of each obstruction? Does the game use a standard obstruction size for most entities of a certain type for example: do all trees use the same obstruction radius except where otherwise specified?
-
Speaking of the maths functions, I recently spent some time writing faster algorithms for the fixed point trig functions. The performance improvement is about double for both atan2 and the sincos function with improved accuracy in the case of the atan2 function. Hopefully that is helpful in some way for what you are doing. Here is the ticket:
http://trac.wildfiregames.com/ticket/2109
Also I agree with you that it doesn't make sense that methods like Zero and Pi create new objects instead of providing a reference to a predefined const object. Personally I got around that by making the paramaterised constructor public so that I could define static const objects -- for example so that I could define a static const lookup table that is evalulated at compile time.
-
Nice work redfox! This is how to get breakthrough performance: http://www.wildfireg...65
Porting the game to C# is a terrible idea. Not only will it break linux portability making the game reliant on mono, but it will never be as fast as well written C/C++. The answer to the performance issues is patience and hard work on the code base not magic language fixes. The current fundraiser is a recognition of this.
-
This seems the relevant place to post this so: I have started working on a few small optimisations for the fixed point library starting with http://trac.wildfiregames.com/ticket/2109 with some more planned as time permits.
-
Awesome to see progress, even if you are dissappointed with the results it is still a giant leap in the right direction.
-
Are there any more thoughts on this or does this thread need some benchmarks to move forward?
I've seen mention of concern about C++11 leading to dropping support for certain platforms. Using C++11 will make no difference to the end user aside from the free performance improvements, it will not change platform compatibility for the end user. As I've mentioned above all the major compilers support C++11 I'm not sure what older compilers are worth mentioning however as may be seen in the link given above even the intel compiler supports C++11. The only potential restriction would be to use only the features supported by MSVC 2010.
The use of Boost makes no difference, using C++11 with Boost will improve Boost's performance. The latest versions of Boost make use of C++11 features conditionally on the compilers support and the C++03 versions will compile with a C++11 compiler.
-
Ok, well you convinced me that is OK to use direct ancient sources, but how could we discern what things to put and what things to put not based on the OT. If we base the hebrews on the OT, then their monks would have the hability of splitting the waters and their soldiers the hability of destroying walls dancing.
I would exclude miraculous stuff like the splitting of the red sea, or destruction of the walls of Jericho from the general civ. It might be interesting to give them heros with powers based off some of the miraculous events in the OT. However the things you mention would not have been expected of a levitical priest. The OT sees those events as incredible miraculous events. Levitical priests had a much less miraculous job of making sacrifices on behalf of the people, looking after the temple etc. One of the defining features of the Israelite nation was its temple be it Solomons temple or the 2nd temple. Their way of life centred around God and the temple that should probably the defining feature of the civ. Off the top of my head one potential unit would be a stone slinger a very common weapon mentioned a number of times in the OT for which much archaeological evidence has been found.
-
You should only use mainstream archeological science and researches for all factions (not limited to jews). You shouldn't base the civilization features on a book/work (whatever the book/work is) that is not a scientific or historiographical study (and i don't mean national geographic/history channel/discovery channel documentaries, no offence alpha). You shouldn't use the bible to create the jews, but an historiographic study on the bible instead.
Let me explain, if the bible (a non scientific book) says the jews were "X shaped", you shouldn't just say "the jews will be X shaped" but find an historiographical study of the bible saying "This claim from the bible where it says that jews were X shaped is true" and then say "the jews will be X shaped".
I don't mean that the bible has non-cientific or fake things, just that the bible (even if its content was true), was not written by scientific-post enlightment-historians and therefore should not be considered for the game until a modern day study of it confirms its claims to be true. Imagine it like a filter, we should use the filter of historiography and archeology, if its true or likely to be true what the bible says, there must be studies about it, and we should use the results of those studies and not the bible itself as inspiration.
Actually this view is indefensible. To say that all post enlightenment historians wrote without bias or purpose is simply not true (the implication of only being able to trust post enlightenment history). Actually if we were to take this view we would know almost nothing about the ancient world. For example, by that argument we would have to say Julius Caesar didn't exist, we would have to disregard the writings of historians like Seutonius, Tacitus, Josephus, Plini because they are for the most part not "scientifically verifiable". No the historian is dependent on histories like the Old Testament to make sense of the Archaeological record. HOWEVER generally the Old Testament is frowned upon as a historical source because of it's religious context, again though this is poor scholarship for the simple reason that most of our sources from the ancient world have religious elements and without these texts we would know almost nothing about the civilisations they were written by. Hear me correctly here, I'm not saying these sources should be trusted without question however what I am saying is that it is poor scholarship to disregard them on the basis of their ideology.
Another very large concern relevant to this discussion is that near eastern chronology is in no way a perfect science. Talking for example about Solomon's empire not existing is a bit of a leap, it takes only a little trip into archaeological scholarship and chronology to see this. Tools like radio carbon dating or dendrochronology are only now making an impact in chronology, for a long time and perhaps even now they were rejected in favour of the old methods of dating. There are many many very poor or circular arguments that are accepted as truth in the Archaeological world and espoused as fact to the public. One instructive example is the dating of Lachish (an Israelite city) level III. The dating of the destruction of this level of Lachish was originally based on the dating of a number of ostraca found in its ruins (a type of letter generally written on pottery). The date initially given for this level of Lachish was derived from analysis of these letters by a Hebrew specialist named Torczyner. However, these dates were revised by about 150 years by Hebrew specialists over a number of years of dissecting his arguments. The archaeological world seemed completely oblivious to this though and still continued to use the incorrect dates to peg the dating of Lachish III. Given that Lachish was used a reference date this had pretty big consequences. A very interesting book on this topic (near eastern chronology), though sadly out of print now, is "Centuries of Darkness" by Peter James et al. My point is this: what we know about the ancient near east is a very large moving target and it is certainly not the perfect post enlightenment science it is made out to be. In my opinion basing the Hebrews off the O.T. would be reasonable.
-
3
-
-
This looks great! Awesome results!
template<unsigned TSIZE> struct _global_pool { static dynamic_pool<TSIZE, true> pool; };
template<unsigned TSIZE> dynamic_pool<TSIZE, true> _global_pool<TSIZE>::pool(true);Am I right in understanding the second line as making calls to dynamic_pool refer to the static dynamic_pool inside of _global_pool?
Also whilst talking about templates, there is a new feature of C++11 that allows you to make template aliases, with pretty much the same effect as the inheritance you use here to hide the allocator parameter. I'm not sure if there is any benefit over the current method though I am just posting it for interests sake.
https://blogs.oracle.com/pcarlini/entry/template_aliases
I'd like to have a look at the source for the allocators and the pools, is there somewhere you could put it up so I can look through it all. I have some ideas for some optimisations that would require using the memory pool system in 0AD and I'd like to benchmark them.
-
Also c++11 is backwards compatible with c++03 etc.
Finally OS support shouldn't be an issue the only potential os problem is FreeBSD and they are moving to use clang now instead of the old GCC 4.2 version they were using due to licensing issues.
EDIT:
I found a list of VC2010 supported C++11 features:
http://blogs.msdn.com/b/vcblog/archive/2010/04/06/c-0x-core-language-features-in-vc10-the-table.aspx
Unfortunately range based for loops are not in that list.
-
http://wiki.apache.org/stdcxx/C%2B%2B0xCompilerSupport
The above link shows the support for c++11. All the major compilers (including clang) support the perf related features we want to use. Vc++ stl maintainer estimates a 20 percent perf improvement just from move constructors. Below is a good explanation of rvalue references and move constructors. This is certainly not just a matter of making the code look pretty.
-
Not all the features of C++11 are implemented in VS2010 or the standard library that ships with VS2010. To make proper use of the C++11 features you must compile with VS2012. Although not even 2012 is feature complete but we probably won't be using things like proper variadic templates etc.
I think this is a no brainer for the code base though, in my opinion the highest priority should be implementing move constructors. We get the free upgrade of the STL using std::move(), std::forward and emplace_back() but we still need to implement the move constructors in our own classes.
If you're not up to reading about C++11 the following is a fantastic video on C++11 by Bjarne Stroustrap.
http://channel9.msdn...rup-Cpp11-Style
And there are a number of other fantastic lectures from that conference on the various new features.
-
For the memory pool I'm using a custom implementation that is very light-weight. The code for it looks ugly because it's so heavily optimized, but that's something we'll have to live with to get the performance. The guy at codeproject does a lot of unnecessary processing that slows things down. I use a single-linked list for the freelist and an additional 'available' counter. I'll omit any debug code to keep this already complex sample simple. I'm using a C-like approach here to get the maximum juice out of the application. The pool objects are always dynamically allocated as [sizeof(pool) + bufferSize]. This is a clever trick to avoid allocating a secondary buffer inside the pool. You might also notice that I'm placing the freelist next pointer inside the actual memory block. This requires TSIZE to be atleast sizeof pointer. Normally this is pretty dangerous, but in debug mode I revert to a conventional struct where the next pointer is before data. I also write a guard value into the place where the next pointer will be during release mode, so that I can catch any invalid writes to deleted pointers. This really makes the code somewhat complex in debug mode and we might not even need it, but its nice to have an assertion when you make a mistake. In release mode the pool has no real overhead. If the pool is used as a temporary dynamic memory source with no deallocs, we could change the alloc function to prefer new nodes from instead of . You can clear the state of the pool by just calling ::clear() - the pool will forget its freed list and reset available count. Also, we don't really need the 'freed' counter - I'm just using it for accurate estimates of pool memory usage.
You're right that codeproject fellow uses a lot of unneccessary stuff, I was just looking to see the approach people take. His use of the doubly linked list is pretty serious overkill when you're essentially treating the linked list as a stack.
I work through and decipher ugly old C/C++ everyday and this code is very clear and easy to understand so I wouldn't worry about that. I really like the use of the union there, a separate pointer would just be unnecessary used space. Perhaps it makes sense to have a second memory pool type to specifically support temporary allocation. Though switching the priority in the current implementation would only cost an extra cycle for allocation off the freed list, but I guess every cycle counts.
-
I didn't track the memory consumption of the profiler, but my machine has 6GB tri channel ram.
Haha indeed it's a staggering number of allocs and notice also the number of reallocs shown in the general summary. That is a huge amount of memory copying combined with allocation.
Using a memory pool as you suggested should shave quite a lot of time off of each frame. What sort of implementation are you using behind the scenes, I had a look at one yesterday that used two doubly linked lists to manage the list of used and free blocks.
http://www.codeproject.com/Articles/27487/Why-to-use-memory-pool-and-how-to-implement-it
This is a bit off topic but another thing I've been looking at whilst this discussion has been going on is implementing move constructors in some of the basic value objects in 0AD, some potential candidates are classes like CVectorXD but I need to have a closer look at the code. We already get the benefit of the STL containers using move constructors by compiling with VC2010 and above -- which is in fact another point to be made -- the alpha releases should all be compiled with the gcc c++ 11 flags and with visual studio 2012 to make sure we get the STL/std library C++11 performance improvements.
-
Just a few more profiler images to throw into the fray.
Revision 13491, single player match against aegis bot. I basically left the profiler going for the duration of the match. The following is the memory usage for the duration of the game. The first section is the main menu, the second is the initial game, the late game peak is using the developer overlay to reveal the map.
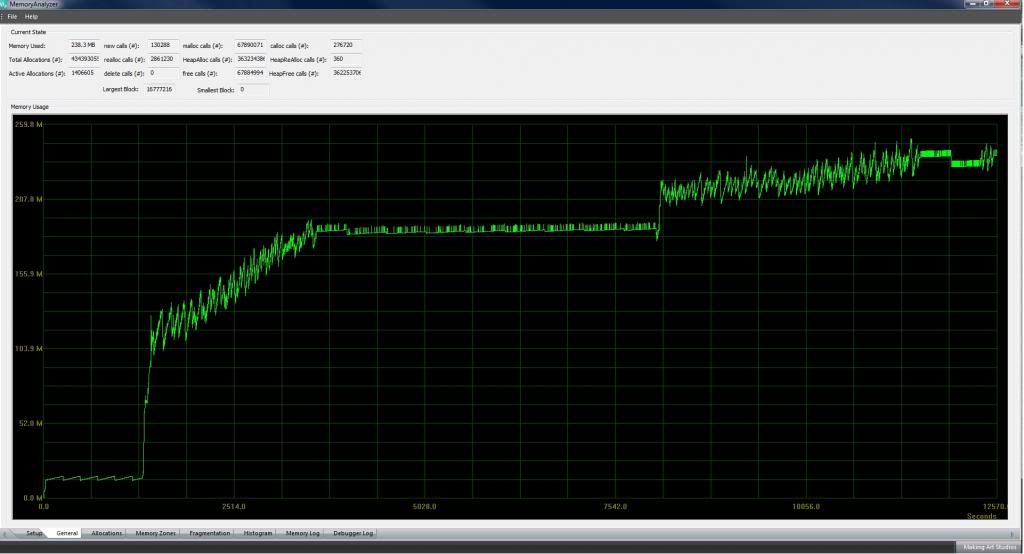 .
.Summary memory allocation histograms for the run. The numbers are so large they don't display properly.
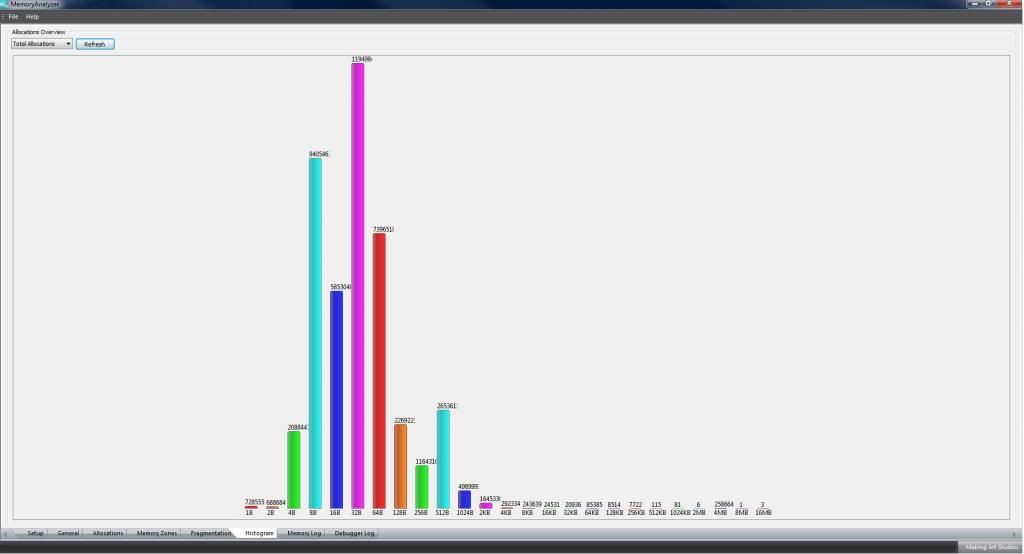
Three images of sections the CRT heap towards the end of the game. As redfox has already mentioned, there are a HUGE number of very small allocations. Indicated both in the following images and in the above histogram.
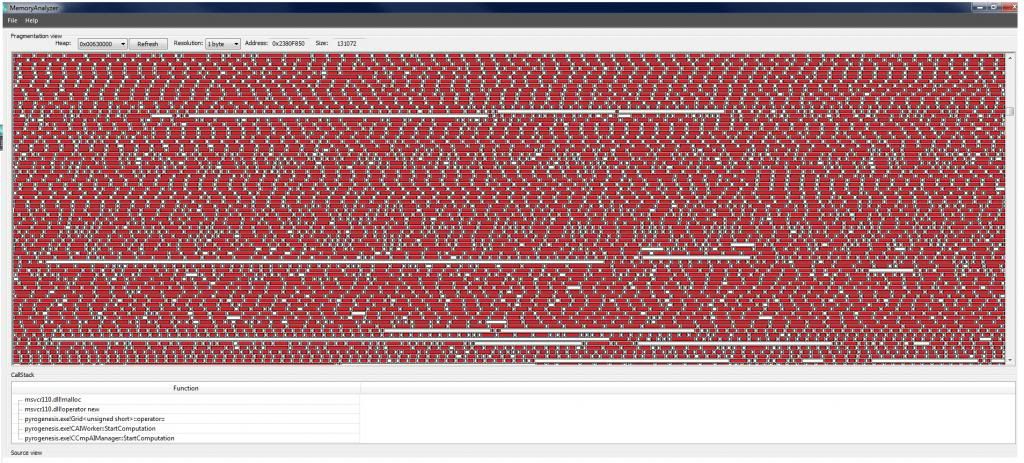
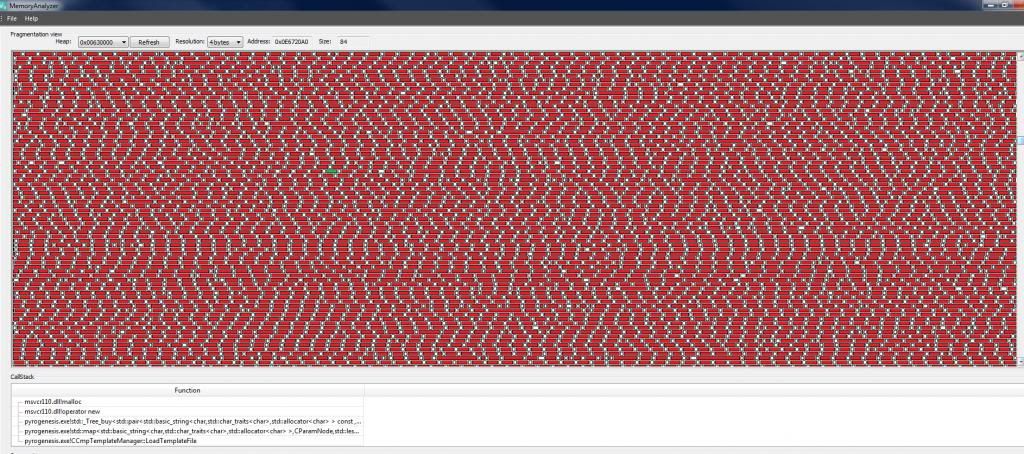
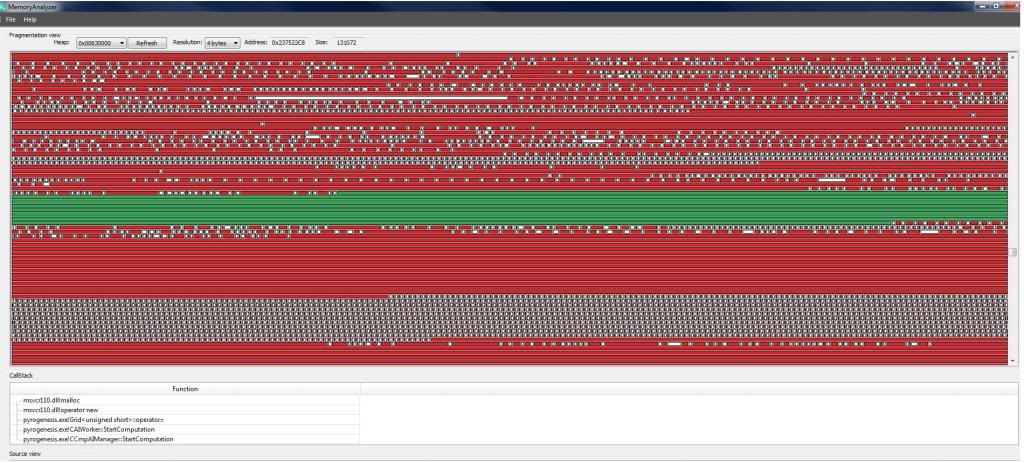
The green highlighted section is just the allocated memory block I selected.
-
1
-
-
Had a look again this morning, helps to be a little more awake. Somehow thebs.civ had been modified, which is bizare because I certainly didn't change anything. Revert fixes the issue. Sorry about the false alarm!!!
Memory Pools
in Game Development & Technical Discussion
Posted · Edited by Thanduel
Just to start there was a large effort originally to show that memory was a significant issue. This can be seen in the original posts connected with this work and all the profiling posted in that thread. Whilst I do not think that the memory improvement would solve the performance problems related to algorithmic issues I do think it will be more than just a fractional improvement. However, to verify this my plan is to target specific areas that are critical to performance first like the unit ranging code or the pathfinder. I agree that just changing the entire codebase to use a memory pooling system without first verifying that it is helpful would be stupid a lot of work for little benefit.
Thanks for the link to paper.